eddystore Storage and parallel processing of eddy covariance data
eddystore is a facility for the storage and processing of eddy covariance data for the NERC community. eddystore can automatically process uploaded data, allowing near-real-time flux calculation with automated raw-data uploads. Processing can be carried out in parallel to achieve fast calculation times for long time series. The system can be accessed via a web interface or via a Linux command-line interface.
eddystore comprises several components:
- the JASMIN storage and computation hardware
- three pieces of software:
- the eddypro fortran program which performs the flux calculations
- an R package “eddystore” which contains:
- functions which translate the user processing requirements into computation instructions on jasmin, and
- R scripts which carry these instructions out on a scheduled basis as cron jobs
- a shiny app which allows jobs to be run on jasmin via a web browser
Processing jobs can be created manually via a web browser, or run automatically on a scheduled basis. The web interface allows a processing job to be submitted for a particular site and time period. Raw data can be uploaded via dropbox, or preferably directly to eddystore via SCP or rsync with a JASMIN account. Output data can be downloaded via a web browser or with SCP.
In order to use eddystore via the web browser interface, you need to apply for access at eddystore@ceh.ac.uk.
In order to use eddystore with full flexibility from a Linux command-line interface, you need to do the following:
- apply for access at eddystore@ceh.ac.uk, and also
- apply for a JASMIN account, with access to the eddystore group workspace.
In the latter case (via the Linux command-line interface), eddystore works as a set of functions within R.
Running R on JASMIN
To run R, you first need to login to one of the sci- machines from the login server e.g.
ssh -A -X sci1.jasmin.ac.uk
You then need to load a software environment which gives access to an installation of R. This is most easily done by loading the default “jasr” environment:
module load jasr
and thereafter, R is available from the command line:
R
Installing the eddystore R package
Once you have R working, you can install the eddystore R package from GitHub, by typing the following at the R command prompt:
library(devtools)
install_github("NERC-CEH/eddystore", auth_token = "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")
library(eddystore)
and help is available in the standard R manner:
?eddystore
vignettes("eddystore")
- Accessing eddystore
- Uploading raw daw eddystore
- Using eddystore via the command line
- Using eddystore via a web browswer
- How it works
- Background
- Resources
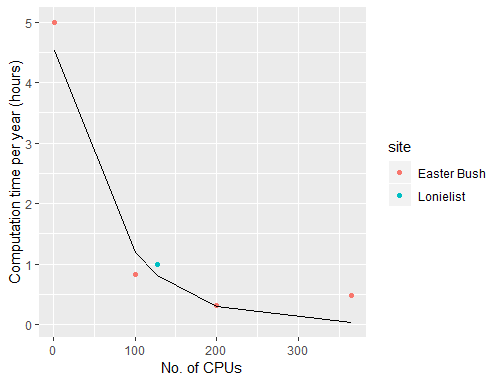
Splitting the processing into a number of jobs run in parallel speeds the computation time, approximately in line with the graph below, but will be greater with longer runs.
If anything here is confusing, or if I’ve missed important details, please submit an issue.
The source for this site is based this.