Retrieving Models
Due to the total size of the ENMs currently included in
elements (1.8GB when compressed, 7.5GB in memory) the ENMs
are not exported in a .rda object. Instead they are made available
through a filehash (Peng, 2005) database, which provides
access to the ENMs without loading all models into memory. To access the
ENMs a connection to this database must be initialised using
elements::startup. As mentioned above the Github repository
does not include the “./inst/extdata/Models” object containing all the
ENMs, the elements::startup will check whether the
“./inst/extdata/Models” is present and if it is not found will load the
“./inst/testdata/TestModels” models instead. The models to load can also
be accessed by passing “all” or “test” to the ‘models’ argument of
elements::startup.
elements::startup()
#> elements startup completed.
model <- elementsEnv$Models[["stellaria_graminea"]]#>
#> Call:
#> svm(formula = Presence ~ L + M + N + R + S + SD + GP + tmax_sm +
#> tmin_wt + prec_sm + prec_wt, data = data, type = "C-classification",
#> probability = TRUE)
#>
#>
#> Parameters:
#> SVM-Type: C-classification
#> SVM-Kernel: radial
#> cost: 0.01
#>
#> Number of Support Vectors: 53671Generating Predictions
The raw ENMs retrieved using the method above can be used as regular
e1071 SVM model objects. Alternatively, the helper function
elements::predict_occ_taxon retrieves a model using the
method above, generates predictions, and formats the results as a data
frame.
results <- elements::predict_occ_taxon(taxon = "stellaria_graminea", predictors = elements::ExampleData1, pa = "Present", limit = NULL, dp = 2, append = "ids")#> Present
#> 1 0.10
#> 2 0.08
#> 3 0.09
#> 4 0.13
#> 5 0.07
#> 6 0.48An additional helper function elements::predict_occ can
generate predictions for multiple taxa, by either specifing the taxa to
model in the ‘taxa’ argument, or by setting ‘taxa’ to NULL and including
an additional column in the predictors data frame named
‘taxon_code’.
results <- elements::predict_occ(taxa = NULL, predictors = elements::ExampleData2, pa = "Present", limit = NULL, holdopt = NULL, dp = 2, append = "ids")#> taxon_code Present
#> 201 silene_flos-cuculi_aggr 0.02
#> 202 silene_flos-cuculi_aggr 0.00
#> 203 silene_flos-cuculi_aggr 0.17
#> 204 silene_flos-cuculi_aggr 0.01
#> 205 silene_flos-cuculi_aggr 0.28
#> 206 silene_flos-cuculi_aggr 0.00Two helper arguments provide additional functionality in controlling
model use. First, is the ‘limit’ argument, which assigns probability
values of zero if one or more predictors are outside a specified range
e.g. the 10% and 90% quantiles (see elements::NicheWidths).
Second, is the ‘holdopt’ argument, which holds specified variable values
at their optima (as defined by the mean value present in
elements::NicheWidths).
As a simple demonstration, below two sets of predictions for Stellaria graminea are generated, holding all variables apart from N at their optima: 1) with no limit set, and 2) with a limit set to the 1% and 99% quantiles.
n_gradient <- data.frame("N" = seq(0, 10, 0.01))
vary_N_no_limit <- elements::predict_occ_taxon(taxon = "stellaria_graminea", predictors = n_gradient,
pa = "Present", limit = NULL, holdopt = c("tmax_sm", "tmin_wt", "prec_wt", "prec_sm", "GP", "L", "M", "R", "S", "SD"),
dp = 2, append = "predictors")
vary_N_q01_q99 <- elements::predict_occ_taxon(taxon = "stellaria_graminea", predictors = n_gradient,
pa = "Present", limit = "q01_q99", holdopt = c("tmax_sm", "tmin_wt", "prec_wt", "prec_sm", "GP", "L", "M", "R", "S", "SD"),
dp = 2, append = "predictors")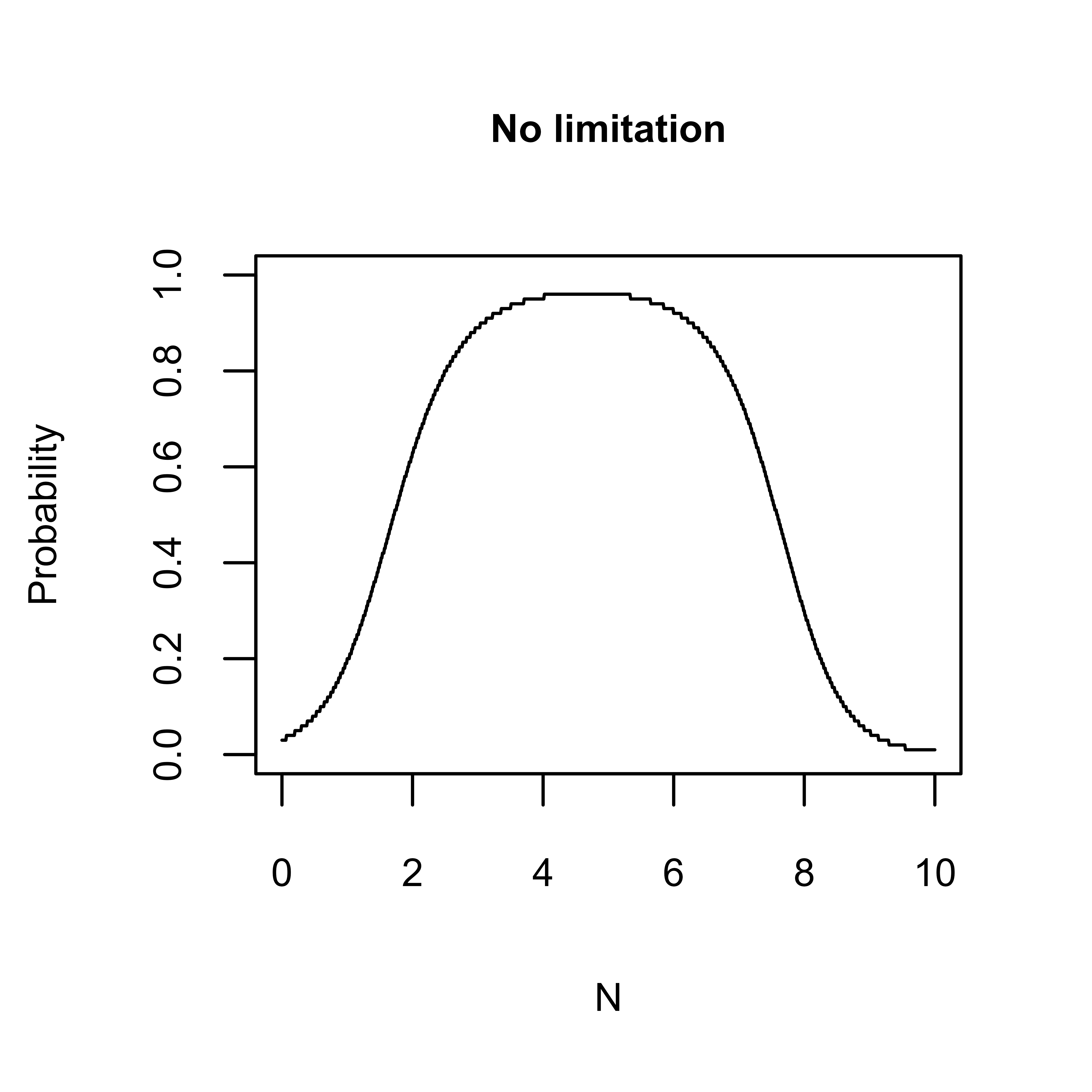
Please note that as ten out of the eleven variables are held at their
optima the predicted probabilities will be high as the influence of
unsuitable N values will be partially offset. Consequently, the shape of
the response curves above will be wider than the corresponding PDP plot
produced with the elements::plot_me function (see the
Model Inspection).
Environmental filtering
elements can also be used to filter species pools based
on a given set of predictor values using the function
elements::env_filter. Two sets of methods are available: 1)
“svm” which generates predictions using
elements::predict_occ and uses the resultant probability
values; and 2) “mean” and “median” which calculates the normalised
euclidean distance between the values supplied in the ‘predictors’
argument and the mean or median niche positions as present in
elements::NicheWidths.
NOTE: The mean and median methods are only included for demonstrative purposes only and should not be used in practice as they do not consider the joint distribution of variables as expressed through the SVM model hypervolumes.
The option to apply the elements::envelope_filter
function, which first screens the supplied taxa to check whether the
predictor values are within a given range as supplied to the ‘limit’
argument (“min_max”, “q01_q99”, “q05_q95”, “q10_q90”, “q25_q75”), is
controlled by the ‘screen’ argument; elements::env_filter
will then only run the more computationally expensive
elements::predict_occ or
elements::calc_distance functions for the taxa within the
limits. This is highly recommended as it usually results in a 95%
reduction in the number of taxa being supplied to
elements::predict_occ or
elements::calc_distance, greatly improving performance.
For example, below elements::env_filter is applied to
all taxa in elements::ModelledTaxaCodes using the svm
method, with the predictors derived from
elements::ExampleScenarios.
filter_results <- elements::env_filter(predictors = elements::ExampleScenarios[1,],
taxa = elements::ModelledTaxaCodes,
screen = TRUE, method = "svm", limit = "min_max",
exclude = NULL, threshold = NULL,
append = "ids")#> scenario_code scenario_stage climate_scenario timeslice scenario_name
#> 1 a.i baseline historical 2025 Climate Change
#> 2 a.i baseline historical 2025 Climate Change
#> 3 a.i baseline historical 2025 Climate Change
#> 4 a.i baseline historical 2025 Climate Change
#> 5 a.i baseline historical 2025 Climate Change
#> 6 a.i baseline historical 2025 Climate Change
#> 7 a.i baseline historical 2025 Climate Change
#> 8 a.i baseline historical 2025 Climate Change
#> 9 a.i baseline historical 2025 Climate Change
#> 10 a.i baseline historical 2025 Climate Change
#> taxon_code Present
#> 1 abies_alba 0.056
#> 2 abietinella_abietina_aggr 0.010
#> 3 acer_campestre_aggr 0.027
#> 4 acer_negundo 0.000
#> 5 acer_platanoides_aggr 0.024
#> 6 acer_pseudoplatanus 0.254
#> 7 acer_tataricum 0.001
#> 8 achillea_millefolium_aggr 0.053
#> 9 achillea_ptarmica 0.156
#> 10 aconitum_napellus_aggr 0.033In practice, given the limited size of regional species pools and/or
interest in a particular group of taxa only it is often more practical
to supply a reduced list of taxa to
elements::env_filter.
Niche overlap
The ability to calculate the niche overlap between taxa is provided
through the elements::calc_overlap function, below the
niche overlaps for the taxa present in
elements::ExamplePlots are displayed.
elements::calc_overlap(taxa = elements::ExamplePlots$taxon_code)
#> Warning in reshapeWide(data, idvar = idvar, timevar = timevar, varying =
#> varying, : multiple rows match for variable=M: first taken
#> Warning in reshapeWide(data, idvar = idvar, timevar = timevar, varying =
#> varying, : multiple rows match for variable=N: first taken
#> Warning in reshapeWide(data, idvar = idvar, timevar = timevar, varying =
#> varying, : multiple rows match for variable=R: first taken
#> Warning in reshapeWide(data, idvar = idvar, timevar = timevar, varying =
#> varying, : multiple rows match for variable=L: first taken
#> Warning in reshapeWide(data, idvar = idvar, timevar = timevar, varying =
#> varying, : multiple rows match for variable=S: first taken
#> Warning in reshapeWide(data, idvar = idvar, timevar = timevar, varying =
#> varying, : multiple rows match for variable=GP: first taken
#> Warning in reshapeWide(data, idvar = idvar, timevar = timevar, varying =
#> varying, : multiple rows match for variable=SD: first taken
#> Warning in reshapeWide(data, idvar = idvar, timevar = timevar, varying =
#> varying, : multiple rows match for variable=tmax_sm: first taken
#> Warning in reshapeWide(data, idvar = idvar, timevar = timevar, varying =
#> varying, : multiple rows match for variable=tmin_wt: first taken
#> Warning in reshapeWide(data, idvar = idvar, timevar = timevar, varying =
#> varying, : multiple rows match for variable=prec_sm: first taken
#> Warning in reshapeWide(data, idvar = idvar, timevar = timevar, varying =
#> varying, : multiple rows match for variable=prec_wt: first taken
#> taxon_code_1 taxon_code_2 M
#> 1 eupatorium_cannabinum_aggr phragmites_australis_aggr 0.7097595
#> 2 eupatorium_cannabinum_aggr equisetum_palustre 0.7580428
#> 3 eupatorium_cannabinum_aggr juncus_subnodulosus 0.7561738
#> 4 eupatorium_cannabinum_aggr galium_palustre_aggr 0.5643536
#> 5 eupatorium_cannabinum_aggr mentha_aquatica_aggr 0.5819738
#> 6 eupatorium_cannabinum_aggr valeriana_excelsa_aggr 0.7902977
#> 7 eupatorium_cannabinum_aggr galium_uliginosum 0.7566704
#> 8 eupatorium_cannabinum_aggr cirsium_palustre 0.9010505
#> 9 eupatorium_cannabinum_aggr angelica_sylvestris_aggr 0.8563125
#> 10 eupatorium_cannabinum_aggr scrophularia_auriculata_aggr 0.7998412
#> 11 eupatorium_cannabinum_aggr caltha_palustris 0.6870644
#> 12 eupatorium_cannabinum_aggr crepis_paludosa 0.7852360
#> 13 eupatorium_cannabinum_aggr succisa_pratensis 0.7913891
#> 18 eupatorium_cannabinum_aggr eupatorium_cannabinum_aggr 1.0000000
#> 19 eupatorium_cannabinum_aggr filipendula_ulmaria_aggr 0.7972195
#> 21 eupatorium_cannabinum_aggr epilobium_hirsutum 0.7915687
#> 24 eupatorium_cannabinum_aggr dactylorhiza_incarnata_aggr 0.7587943
#> 25 eupatorium_cannabinum_aggr silene_flos-cuculi_aggr 0.7002306
#> 33 eupatorium_cannabinum_aggr vicia_cracca_aggr 0.7783713
#> 34 eupatorium_cannabinum_aggr carex_acutiformis 0.7965440
#> 50 eupatorium_cannabinum_aggr epilobium_parviflorum 0.7563185
#> 74 eupatorium_cannabinum_aggr cardamine_hirsuta 0.3515142
#> 79 eupatorium_cannabinum_aggr salix_pentandra 0.7987939
#> 88 eupatorium_cannabinum_aggr thalictrum_flavum 0.5529512
#> 90 eupatorium_cannabinum_aggr cirsium_arvense 0.7222333
#> 93 phragmites_australis_aggr equisetum_palustre 0.7037032
#> 94 phragmites_australis_aggr juncus_subnodulosus 0.7181502
#> 95 phragmites_australis_aggr galium_palustre_aggr 0.8017599
#> 96 phragmites_australis_aggr mentha_aquatica_aggr 0.8340908
#> 97 phragmites_australis_aggr valeriana_excelsa_aggr 0.8011252
#> 98 phragmites_australis_aggr galium_uliginosum 0.6275732
#> 99 phragmites_australis_aggr cirsium_palustre 0.8068702
#> 100 phragmites_australis_aggr angelica_sylvestris_aggr 0.7310338
#> 101 phragmites_australis_aggr scrophularia_auriculata_aggr 0.6865911
#> 102 phragmites_australis_aggr caltha_palustris 0.6132449
#> 103 phragmites_australis_aggr crepis_paludosa 0.6430869
#> 104 phragmites_australis_aggr succisa_pratensis 0.6923712
#> 106 phragmites_australis_aggr phragmites_australis_aggr 1.0000000
#> 109 phragmites_australis_aggr eupatorium_cannabinum_aggr 0.7097595
#> 110 phragmites_australis_aggr filipendula_ulmaria_aggr 0.6597661
#> 112 phragmites_australis_aggr epilobium_hirsutum 0.8454603
#> 115 phragmites_australis_aggr dactylorhiza_incarnata_aggr 0.7290988
#> 116 phragmites_australis_aggr silene_flos-cuculi_aggr 0.5382725
#> 124 phragmites_australis_aggr vicia_cracca_aggr 0.6025329
#> 125 phragmites_australis_aggr carex_acutiformis 0.8730398
#> 141 phragmites_australis_aggr epilobium_parviflorum 0.8553552
#> 165 phragmites_australis_aggr cardamine_hirsuta 0.2777306
#> 170 phragmites_australis_aggr salix_pentandra 0.7480951
#> 179 phragmites_australis_aggr thalictrum_flavum 0.8245923
#> 181 phragmites_australis_aggr cirsium_arvense 0.5634101
#> 184 equisetum_palustre juncus_subnodulosus 0.9522091
#> 185 equisetum_palustre galium_palustre_aggr 0.6784659
#> 186 equisetum_palustre mentha_aquatica_aggr 0.6942743
#> 187 equisetum_palustre valeriana_excelsa_aggr 0.8860538
#> 188 equisetum_palustre galium_uliginosum 0.9031638
#> 189 equisetum_palustre cirsium_palustre 0.8132412
#> 190 equisetum_palustre angelica_sylvestris_aggr 0.8921630
#> 191 equisetum_palustre scrophularia_auriculata_aggr 0.8938316
#> 192 equisetum_palustre caltha_palustris 0.8453228
#> 193 equisetum_palustre crepis_paludosa 0.9060700
#> 194 equisetum_palustre succisa_pratensis 0.6053050
#> 196 equisetum_palustre phragmites_australis_aggr 0.7037032
#> 198 equisetum_palustre equisetum_palustre 1.0000000
#> 199 equisetum_palustre eupatorium_cannabinum_aggr 0.7580428
#> 200 equisetum_palustre filipendula_ulmaria_aggr 0.9147716
#> 202 equisetum_palustre epilobium_hirsutum 0.8212250
#> 205 equisetum_palustre dactylorhiza_incarnata_aggr 0.9153949
#> 206 equisetum_palustre silene_flos-cuculi_aggr 0.7897131
#> 214 equisetum_palustre vicia_cracca_aggr 0.5558800
#> 215 equisetum_palustre carex_acutiformis 0.7927488
#> 231 equisetum_palustre epilobium_parviflorum 0.8275408
#> 255 equisetum_palustre cardamine_hirsuta 0.1739213
#> 260 equisetum_palustre salix_pentandra 0.9093252
#> 269 equisetum_palustre thalictrum_flavum 0.6547658
#> 271 equisetum_palustre cirsium_arvense 0.4988674
#> 274 juncus_subnodulosus galium_palustre_aggr 0.7012664
#> 275 juncus_subnodulosus mentha_aquatica_aggr 0.7151937
#> 276 juncus_subnodulosus valeriana_excelsa_aggr 0.9008481
#> 277 juncus_subnodulosus galium_uliginosum 0.8734535
#> 278 juncus_subnodulosus cirsium_palustre 0.8141704
#> 279 juncus_subnodulosus angelica_sylvestris_aggr 0.8859853
#> 280 juncus_subnodulosus scrophularia_auriculata_aggr 0.9088567
#> 281 juncus_subnodulosus caltha_palustris 0.8393288
#> 282 juncus_subnodulosus crepis_paludosa 0.8850223
#> 283 juncus_subnodulosus succisa_pratensis 0.6035518
#> 284 juncus_subnodulosus juncus_subnodulosus 1.0000000
#> 285 juncus_subnodulosus phragmites_australis_aggr 0.7181502
#> 287 juncus_subnodulosus equisetum_palustre 0.9522091
#> 288 juncus_subnodulosus eupatorium_cannabinum_aggr 0.7561738
#> 289 juncus_subnodulosus filipendula_ulmaria_aggr 0.8864502
#> 291 juncus_subnodulosus epilobium_hirsutum 0.8449366
#> 294 juncus_subnodulosus dactylorhiza_incarnata_aggr 0.9366607
#> 295 juncus_subnodulosus silene_flos-cuculi_aggr 0.7457091
#> 303 juncus_subnodulosus vicia_cracca_aggr 0.5559067
#> 304 juncus_subnodulosus carex_acutiformis 0.8129196
#> 320 juncus_subnodulosus epilobium_parviflorum 0.8498545
#> 344 juncus_subnodulosus cardamine_hirsuta 0.1730043
#> 349 juncus_subnodulosus salix_pentandra 0.9257529
#> 358 juncus_subnodulosus thalictrum_flavum 0.6697780
#> 360 juncus_subnodulosus cirsium_arvense 0.4972390
#> 363 galium_palustre_aggr mentha_aquatica_aggr 0.9650184
#> 364 galium_palustre_aggr valeriana_excelsa_aggr 0.7497058
#> 365 galium_palustre_aggr galium_uliginosum 0.5935895
#> 366 galium_palustre_aggr cirsium_palustre 0.6625985
#> 367 galium_palustre_aggr angelica_sylvestris_aggr 0.6252482
#> 368 galium_palustre_aggr scrophularia_auriculata_aggr 0.6359656
#> 369 galium_palustre_aggr caltha_palustris 0.6278239
#> 370 galium_palustre_aggr crepis_paludosa 0.5955168
#> 371 galium_palustre_aggr succisa_pratensis 0.5130596
#> 372 galium_palustre_aggr juncus_subnodulosus 0.7012664
#> 373 galium_palustre_aggr phragmites_australis_aggr 0.8017599
#> 375 galium_palustre_aggr equisetum_palustre 0.6784659
#> 376 galium_palustre_aggr eupatorium_cannabinum_aggr 0.5643536
#> 377 galium_palustre_aggr filipendula_ulmaria_aggr 0.6048706
#> 378 galium_palustre_aggr galium_palustre_aggr 1.0000000
#> 379 galium_palustre_aggr epilobium_hirsutum 0.7603801
#> 382 galium_palustre_aggr dactylorhiza_incarnata_aggr 0.6994673
#> 383 galium_palustre_aggr silene_flos-cuculi_aggr 0.4946227
#> 391 galium_palustre_aggr vicia_cracca_aggr 0.4233755
#> 392 galium_palustre_aggr carex_acutiformis 0.7641250
#> 408 galium_palustre_aggr epilobium_parviflorum 0.7992094
#> 432 galium_palustre_aggr cardamine_hirsuta 0.1403038
#> 437 galium_palustre_aggr salix_pentandra 0.6773638
#> 446 galium_palustre_aggr thalictrum_flavum 0.9377098
#> 448 galium_palustre_aggr cirsium_arvense 0.3805401
#> 451 mentha_aquatica_aggr valeriana_excelsa_aggr 0.7636674
#> 452 mentha_aquatica_aggr galium_uliginosum 0.6102345
#> 453 mentha_aquatica_aggr cirsium_palustre 0.6809233
#> 454 mentha_aquatica_aggr angelica_sylvestris_aggr 0.6421859
#> 455 mentha_aquatica_aggr scrophularia_auriculata_aggr 0.6492796
#> 456 mentha_aquatica_aggr caltha_palustris 0.6188997
#> 457 mentha_aquatica_aggr crepis_paludosa 0.6104017
#> 458 mentha_aquatica_aggr succisa_pratensis 0.5449893
#> 459 mentha_aquatica_aggr juncus_subnodulosus 0.7151937
#> 460 mentha_aquatica_aggr phragmites_australis_aggr 0.8340908
#> 462 mentha_aquatica_aggr equisetum_palustre 0.6942743
#> 463 mentha_aquatica_aggr eupatorium_cannabinum_aggr 0.5819738
#> 464 mentha_aquatica_aggr filipendula_ulmaria_aggr 0.6204406
#> 465 mentha_aquatica_aggr galium_palustre_aggr 0.9650184
#> 466 mentha_aquatica_aggr epilobium_hirsutum 0.7731899
#> 469 mentha_aquatica_aggr dactylorhiza_incarnata_aggr 0.7118754
#> 470 mentha_aquatica_aggr silene_flos-cuculi_aggr 0.5134549
#> 478 mentha_aquatica_aggr vicia_cracca_aggr 0.4508547
#> 479 mentha_aquatica_aggr carex_acutiformis 0.7783723
#> 481 mentha_aquatica_aggr mentha_aquatica_aggr 1.0000000
#> 495 mentha_aquatica_aggr epilobium_parviflorum 0.8118209
#> 519 mentha_aquatica_aggr cardamine_hirsuta 0.1561096
#> 524 mentha_aquatica_aggr salix_pentandra 0.6914168
#> 533 mentha_aquatica_aggr thalictrum_flavum 0.9459272
#> 535 mentha_aquatica_aggr cirsium_arvense 0.4094660
#> 538 valeriana_excelsa_aggr galium_uliginosum 0.7950920
#> 539 valeriana_excelsa_aggr cirsium_palustre 0.8500988
#> 540 valeriana_excelsa_aggr angelica_sylvestris_aggr 0.8649577
#> 541 valeriana_excelsa_aggr scrophularia_auriculata_aggr 0.8767530
#> 542 valeriana_excelsa_aggr caltha_palustris 0.7546361
#> 543 valeriana_excelsa_aggr crepis_paludosa 0.8308505
#> 544 valeriana_excelsa_aggr succisa_pratensis 0.6412631
#> 545 valeriana_excelsa_aggr juncus_subnodulosus 0.9008481
#> 546 valeriana_excelsa_aggr phragmites_australis_aggr 0.8011252
#> 548 valeriana_excelsa_aggr equisetum_palustre 0.8860538
#> 549 valeriana_excelsa_aggr eupatorium_cannabinum_aggr 0.7902977
#> 550 valeriana_excelsa_aggr filipendula_ulmaria_aggr 0.8085228
#> 551 valeriana_excelsa_aggr galium_palustre_aggr 0.7497058
#> 552 valeriana_excelsa_aggr epilobium_hirsutum 0.9260609
#> 553 valeriana_excelsa_aggr valeriana_excelsa_aggr 1.0000000
#> 555 valeriana_excelsa_aggr dactylorhiza_incarnata_aggr 0.9230159
#> 556 valeriana_excelsa_aggr silene_flos-cuculi_aggr 0.6954145
#> 564 valeriana_excelsa_aggr vicia_cracca_aggr 0.5906447
#> 565 valeriana_excelsa_aggr carex_acutiformis 0.8995974
#> 567 valeriana_excelsa_aggr mentha_aquatica_aggr 0.7636674
#> 581 valeriana_excelsa_aggr epilobium_parviflorum 0.9247706
#> 605 valeriana_excelsa_aggr cardamine_hirsuta 0.2012222
#> 610 valeriana_excelsa_aggr salix_pentandra 0.9254020
#> 619 valeriana_excelsa_aggr thalictrum_flavum 0.7351076
#> 621 valeriana_excelsa_aggr cirsium_arvense 0.5345743
#> 624 galium_uliginosum cirsium_palustre 0.7537632
#> 625 galium_uliginosum angelica_sylvestris_aggr 0.8743135
#> 626 galium_uliginosum scrophularia_auriculata_aggr 0.8552374
#> 627 galium_uliginosum caltha_palustris 0.8742083
#> 628 galium_uliginosum crepis_paludosa 0.8970216
#> 629 galium_uliginosum succisa_pratensis 0.5855703
#> 630 galium_uliginosum juncus_subnodulosus 0.8734535
#> 631 galium_uliginosum phragmites_australis_aggr 0.6275732
#> 633 galium_uliginosum equisetum_palustre 0.9031638
#> 634 galium_uliginosum eupatorium_cannabinum_aggr 0.7566704
#> 635 galium_uliginosum filipendula_ulmaria_aggr 0.9413825
#> 636 galium_uliginosum galium_palustre_aggr 0.5935895
#> 637 galium_uliginosum epilobium_hirsutum 0.7393750
#> 638 galium_uliginosum valeriana_excelsa_aggr 0.7950920
#> 640 galium_uliginosum dactylorhiza_incarnata_aggr 0.8396967
#> 641 galium_uliginosum silene_flos-cuculi_aggr 0.8666927
#> 649 galium_uliginosum vicia_cracca_aggr 0.5394910
#> 650 galium_uliginosum carex_acutiformis 0.7109744
#> 652 galium_uliginosum mentha_aquatica_aggr 0.6102345
#> 653 galium_uliginosum galium_uliginosum 1.0000000
#> 666 galium_uliginosum epilobium_parviflorum 0.7450518
#> 690 galium_uliginosum cardamine_hirsuta 0.1606385
#> 695 galium_uliginosum salix_pentandra 0.8375832
#> 704 galium_uliginosum thalictrum_flavum 0.5656025
#> 706 galium_uliginosum cirsium_arvense 0.4879010
#> 709 cirsium_palustre angelica_sylvestris_aggr 0.8706274
#> 710 cirsium_palustre scrophularia_auriculata_aggr 0.8121615
#> 711 cirsium_palustre caltha_palustris 0.7108929
#> 712 cirsium_palustre crepis_paludosa 0.7771720
#> 713 cirsium_palustre succisa_pratensis 0.7752843
#> 714 cirsium_palustre juncus_subnodulosus 0.8141704
#> 715 cirsium_palustre phragmites_australis_aggr 0.8068702
#> 717 cirsium_palustre equisetum_palustre 0.8132412
#> 718 cirsium_palustre eupatorium_cannabinum_aggr 0.9010505
#> 719 cirsium_palustre filipendula_ulmaria_aggr 0.7939268
#> 720 cirsium_palustre galium_palustre_aggr 0.6625985
#> 721 cirsium_palustre epilobium_hirsutum 0.8831002
#> 722 cirsium_palustre valeriana_excelsa_aggr 0.8500988
#> 724 cirsium_palustre dactylorhiza_incarnata_aggr 0.8047214
#> 725 cirsium_palustre silene_flos-cuculi_aggr 0.6640587
#> 733 cirsium_palustre vicia_cracca_aggr 0.7380829
#> 734 cirsium_palustre carex_acutiformis 0.8907189
#> 736 cirsium_palustre mentha_aquatica_aggr 0.6809233
#> 737 cirsium_palustre galium_uliginosum 0.7537632
#> 738 cirsium_palustre cirsium_palustre 1.0000000
#> 750 cirsium_palustre epilobium_parviflorum 0.8491798
#> 774 cirsium_palustre cardamine_hirsuta 0.3212578
#> 779 cirsium_palustre salix_pentandra 0.8411420
#> 788 cirsium_palustre thalictrum_flavum 0.6517729
#> 790 cirsium_palustre cirsium_arvense 0.6805260
#> 793 angelica_sylvestris_aggr scrophularia_auriculata_aggr 0.9170893
#> 794 angelica_sylvestris_aggr caltha_palustris 0.8055523
#> 795 angelica_sylvestris_aggr crepis_paludosa 0.9056937
#> 796 angelica_sylvestris_aggr succisa_pratensis 0.6830603
#> 797 angelica_sylvestris_aggr juncus_subnodulosus 0.8859853
#> 798 angelica_sylvestris_aggr phragmites_australis_aggr 0.7310338
#> 800 angelica_sylvestris_aggr equisetum_palustre 0.8921630
#> 801 angelica_sylvestris_aggr eupatorium_cannabinum_aggr 0.8563125
#> 802 angelica_sylvestris_aggr filipendula_ulmaria_aggr 0.9135040
#> 803 angelica_sylvestris_aggr galium_palustre_aggr 0.6252482
#> 804 angelica_sylvestris_aggr epilobium_hirsutum 0.8452715
#> 805 angelica_sylvestris_aggr valeriana_excelsa_aggr 0.8649577
#> 806 angelica_sylvestris_aggr angelica_sylvestris_aggr 1.0000000
#> 807 angelica_sylvestris_aggr dactylorhiza_incarnata_aggr 0.8703193
#> 808 angelica_sylvestris_aggr silene_flos-cuculi_aggr 0.7757330
#> 816 angelica_sylvestris_aggr vicia_cracca_aggr 0.6445318
#> 817 angelica_sylvestris_aggr carex_acutiformis 0.8087321
#> 819 angelica_sylvestris_aggr mentha_aquatica_aggr 0.6421859
#> 820 angelica_sylvestris_aggr galium_uliginosum 0.8743135
#> 821 angelica_sylvestris_aggr cirsium_palustre 0.8706274
#> 833 angelica_sylvestris_aggr epilobium_parviflorum 0.8176661
#> 857 angelica_sylvestris_aggr cardamine_hirsuta 0.2372650
#> 862 angelica_sylvestris_aggr salix_pentandra 0.8936384
#> 871 angelica_sylvestris_aggr thalictrum_flavum 0.6099805
#> 873 angelica_sylvestris_aggr cirsium_arvense 0.5870335
#> 876 scrophularia_auriculata_aggr caltha_palustris 0.8125830
#> 877 scrophularia_auriculata_aggr crepis_paludosa 0.9389900
#> 878 scrophularia_auriculata_aggr succisa_pratensis 0.6170720
#> 879 scrophularia_auriculata_aggr juncus_subnodulosus 0.9088567
#> 880 scrophularia_auriculata_aggr phragmites_australis_aggr 0.6865911
#> 882 scrophularia_auriculata_aggr equisetum_palustre 0.8938316
#> 883 scrophularia_auriculata_aggr eupatorium_cannabinum_aggr 0.7998412
#> 884 scrophularia_auriculata_aggr filipendula_ulmaria_aggr 0.8655625
#> 885 scrophularia_auriculata_aggr galium_palustre_aggr 0.6359656
#> 886 scrophularia_auriculata_aggr epilobium_hirsutum 0.8263835
#> 887 scrophularia_auriculata_aggr valeriana_excelsa_aggr 0.8767530
#> 888 scrophularia_auriculata_aggr angelica_sylvestris_aggr 0.9170893
#> 889 scrophularia_auriculata_aggr dactylorhiza_incarnata_aggr 0.9272434
#> 890 scrophularia_auriculata_aggr silene_flos-cuculi_aggr 0.7659775
#> 898 scrophularia_auriculata_aggr vicia_cracca_aggr 0.5809815
#> 899 scrophularia_auriculata_aggr carex_acutiformis 0.7795274
#> 901 scrophularia_auriculata_aggr mentha_aquatica_aggr 0.6492796
#> 902 scrophularia_auriculata_aggr galium_uliginosum 0.8552374
#> 903 scrophularia_auriculata_aggr cirsium_palustre 0.8121615
#> 913 scrophularia_auriculata_aggr scrophularia_auriculata_aggr 1.0000000
#> 915 scrophularia_auriculata_aggr epilobium_parviflorum 0.8054368
#> 939 scrophularia_auriculata_aggr cardamine_hirsuta 0.1719251
#> 944 scrophularia_auriculata_aggr salix_pentandra 0.9321729
#> 953 scrophularia_auriculata_aggr thalictrum_flavum 0.6163986
#> 955 scrophularia_auriculata_aggr cirsium_arvense 0.5253327
#> 958 caltha_palustris crepis_paludosa 0.8318584
#> 959 caltha_palustris succisa_pratensis 0.5348685
#> 960 caltha_palustris juncus_subnodulosus 0.8393288
#> 961 caltha_palustris phragmites_australis_aggr 0.6132449
#> 963 caltha_palustris equisetum_palustre 0.8453228
#> 964 caltha_palustris eupatorium_cannabinum_aggr 0.6870644
#> 965 caltha_palustris filipendula_ulmaria_aggr 0.8516895
#> 966 caltha_palustris galium_palustre_aggr 0.6278239
#> 967 caltha_palustris epilobium_hirsutum 0.7230556
#> 968 caltha_palustris valeriana_excelsa_aggr 0.7546361
#> 969 caltha_palustris angelica_sylvestris_aggr 0.8055523
#> 970 caltha_palustris dactylorhiza_incarnata_aggr 0.8162091
#> 971 caltha_palustris silene_flos-cuculi_aggr 0.7605528
#> 979 caltha_palustris vicia_cracca_aggr 0.4728139
#> 980 caltha_palustris carex_acutiformis 0.6994093
#> 982 caltha_palustris mentha_aquatica_aggr 0.6188997
#> 983 caltha_palustris galium_uliginosum 0.8742083
#> 984 caltha_palustris cirsium_palustre 0.7108929
#> 994 caltha_palustris scrophularia_auriculata_aggr 0.8125830
#> 996 caltha_palustris epilobium_parviflorum 0.7254295
#> 1020 caltha_palustris cardamine_hirsuta 0.1510896
#> 1025 caltha_palustris salix_pentandra 0.8052404
#> 1034 caltha_palustris thalictrum_flavum 0.5705237
#> 1036 caltha_palustris cirsium_arvense 0.4265593
#> 1039 crepis_paludosa succisa_pratensis 0.5983802
#> 1040 crepis_paludosa juncus_subnodulosus 0.8850223
#> 1041 crepis_paludosa phragmites_australis_aggr 0.6430869
#> 1043 crepis_paludosa equisetum_palustre 0.9060700
#> 1044 crepis_paludosa eupatorium_cannabinum_aggr 0.7852360
#> 1045 crepis_paludosa filipendula_ulmaria_aggr 0.9092764
#> 1046 crepis_paludosa galium_palustre_aggr 0.5955168
#> 1047 crepis_paludosa epilobium_hirsutum 0.7749348
#> 1048 crepis_paludosa valeriana_excelsa_aggr 0.8308505
#> 1049 crepis_paludosa angelica_sylvestris_aggr 0.9056937
#> 1050 crepis_paludosa dactylorhiza_incarnata_aggr 0.8808559
#> 1051 crepis_paludosa silene_flos-cuculi_aggr 0.8184905
#> 1059 crepis_paludosa vicia_cracca_aggr 0.5643604
#> 1060 crepis_paludosa carex_acutiformis 0.7327002
#> 1062 crepis_paludosa mentha_aquatica_aggr 0.6104017
#> 1063 crepis_paludosa galium_uliginosum 0.8970216
#> 1064 crepis_paludosa cirsium_palustre 0.7771720
#> 1074 crepis_paludosa scrophularia_auriculata_aggr 0.9389900
#> 1076 crepis_paludosa epilobium_parviflorum 0.7605723
#> 1081 crepis_paludosa crepis_paludosa 1.0000000
#> 1100 crepis_paludosa cardamine_hirsuta 0.1593151
#> 1105 crepis_paludosa salix_pentandra 0.8855518
#> 1114 crepis_paludosa thalictrum_flavum 0.5742884
#> 1116 crepis_paludosa cirsium_arvense 0.5101055
#> 1119 succisa_pratensis juncus_subnodulosus 0.6035518
#> 1120 succisa_pratensis phragmites_australis_aggr 0.6923712
#> 1121 succisa_pratensis succisa_pratensis 1.0000000
#> 1122 succisa_pratensis equisetum_palustre 0.6053050
#> 1123 succisa_pratensis eupatorium_cannabinum_aggr 0.7913891
#> 1124 succisa_pratensis filipendula_ulmaria_aggr 0.6252754
#> 1125 succisa_pratensis galium_palustre_aggr 0.5130596
#> 1126 succisa_pratensis epilobium_hirsutum 0.6957711
#> 1127 succisa_pratensis valeriana_excelsa_aggr 0.6412631
#> 1128 succisa_pratensis angelica_sylvestris_aggr 0.6830603
#> 1129 succisa_pratensis dactylorhiza_incarnata_aggr 0.6049017
#> 1130 succisa_pratensis silene_flos-cuculi_aggr 0.5516845
#> 1138 succisa_pratensis vicia_cracca_aggr 0.8853569
#> 1139 succisa_pratensis carex_acutiformis 0.7278087
#> 1141 succisa_pratensis mentha_aquatica_aggr 0.5449893
#> 1142 succisa_pratensis galium_uliginosum 0.5855703
#> 1143 succisa_pratensis cirsium_palustre 0.7752843
#> 1153 succisa_pratensis scrophularia_auriculata_aggr 0.6170720
#> 1155 succisa_pratensis epilobium_parviflorum 0.6535697
#> 1160 succisa_pratensis crepis_paludosa 0.5983802
#> 1179 succisa_pratensis cardamine_hirsuta 0.5367368
#> 1184 succisa_pratensis salix_pentandra 0.6419961
#> 1193 succisa_pratensis thalictrum_flavum 0.5244999
#> 1195 succisa_pratensis cirsium_arvense 0.8614642
#> 1578 filipendula_ulmaria_aggr galium_palustre_aggr 0.6048706
#> 1579 filipendula_ulmaria_aggr epilobium_hirsutum 0.7800793
#> 1580 filipendula_ulmaria_aggr valeriana_excelsa_aggr 0.8085228
#> 1581 filipendula_ulmaria_aggr angelica_sylvestris_aggr 0.9135040
#> 1582 filipendula_ulmaria_aggr dactylorhiza_incarnata_aggr 0.8441103
#> 1583 filipendula_ulmaria_aggr silene_flos-cuculi_aggr 0.8302874
#> 1585 filipendula_ulmaria_aggr phragmites_australis_aggr 0.6597661
#> 1586 filipendula_ulmaria_aggr filipendula_ulmaria_aggr 1.0000000
#> 1587 filipendula_ulmaria_aggr eupatorium_cannabinum_aggr 0.7972195
#> 1588 filipendula_ulmaria_aggr juncus_subnodulosus 0.8864502
#> 1589 filipendula_ulmaria_aggr equisetum_palustre 0.9147716
#> 1591 filipendula_ulmaria_aggr vicia_cracca_aggr 0.5835025
#> 1592 filipendula_ulmaria_aggr carex_acutiformis 0.7484236
#> 1594 filipendula_ulmaria_aggr mentha_aquatica_aggr 0.6204406
#> 1595 filipendula_ulmaria_aggr galium_uliginosum 0.9413825
#> 1596 filipendula_ulmaria_aggr cirsium_palustre 0.7939268
#> 1606 filipendula_ulmaria_aggr scrophularia_auriculata_aggr 0.8655625
#> 1608 filipendula_ulmaria_aggr epilobium_parviflorum 0.7702339
#> 1613 filipendula_ulmaria_aggr crepis_paludosa 0.9092764
#> 1632 filipendula_ulmaria_aggr cardamine_hirsuta 0.1958168
#> 1637 filipendula_ulmaria_aggr salix_pentandra 0.8436914
#> 1646 filipendula_ulmaria_aggr thalictrum_flavum 0.5737131
#> 1648 filipendula_ulmaria_aggr cirsium_arvense 0.5288713
#> 1723 epilobium_hirsutum valeriana_excelsa_aggr 0.9260609
#> 1724 epilobium_hirsutum angelica_sylvestris_aggr 0.8452715
#> 1725 epilobium_hirsutum dactylorhiza_incarnata_aggr 0.8600629
#> 1726 epilobium_hirsutum silene_flos-cuculi_aggr 0.6373472
#> 1727 epilobium_hirsutum epilobium_hirsutum 1.0000000
#> 1728 epilobium_hirsutum phragmites_australis_aggr 0.8454603
#> 1729 epilobium_hirsutum filipendula_ulmaria_aggr 0.7800793
#> 1730 epilobium_hirsutum eupatorium_cannabinum_aggr 0.7915687
#> 1731 epilobium_hirsutum juncus_subnodulosus 0.8449366
#> 1732 epilobium_hirsutum equisetum_palustre 0.8212250
#> 1733 epilobium_hirsutum galium_palustre_aggr 0.7603801
#> 1734 epilobium_hirsutum vicia_cracca_aggr 0.6309195
#> 1735 epilobium_hirsutum carex_acutiformis 0.9458175
#> 1737 epilobium_hirsutum mentha_aquatica_aggr 0.7731899
#> 1738 epilobium_hirsutum galium_uliginosum 0.7393750
#> 1739 epilobium_hirsutum cirsium_palustre 0.8831002
#> 1749 epilobium_hirsutum scrophularia_auriculata_aggr 0.8263835
#> 1751 epilobium_hirsutum epilobium_parviflorum 0.9426363
#> 1756 epilobium_hirsutum crepis_paludosa 0.7749348
#> 1775 epilobium_hirsutum cardamine_hirsuta 0.2453250
#> 1780 epilobium_hirsutum salix_pentandra 0.8592023
#> 1789 epilobium_hirsutum thalictrum_flavum 0.7424179
#> 1791 epilobium_hirsutum cirsium_arvense 0.5893986
#> 1933 dactylorhiza_incarnata_aggr silene_flos-cuculi_aggr 0.7296838
#> 1934 dactylorhiza_incarnata_aggr epilobium_hirsutum 0.8600629
#> 1935 dactylorhiza_incarnata_aggr phragmites_australis_aggr 0.7290988
#> 1936 dactylorhiza_incarnata_aggr filipendula_ulmaria_aggr 0.8441103
#> 1937 dactylorhiza_incarnata_aggr eupatorium_cannabinum_aggr 0.7587943
#> 1938 dactylorhiza_incarnata_aggr juncus_subnodulosus 0.9366607
#> 1939 dactylorhiza_incarnata_aggr equisetum_palustre 0.9153949
#> 1940 dactylorhiza_incarnata_aggr galium_palustre_aggr 0.6994673
#> 1941 dactylorhiza_incarnata_aggr vicia_cracca_aggr 0.5497103
#> 1942 dactylorhiza_incarnata_aggr carex_acutiformis 0.8271937
#> 1943 dactylorhiza_incarnata_aggr valeriana_excelsa_aggr 0.9230159
#> 1944 dactylorhiza_incarnata_aggr mentha_aquatica_aggr 0.7118754
#> 1945 dactylorhiza_incarnata_aggr galium_uliginosum 0.8396967
#> 1946 dactylorhiza_incarnata_aggr cirsium_palustre 0.8047214
#> 1947 dactylorhiza_incarnata_aggr angelica_sylvestris_aggr 0.8703193
#> 1956 dactylorhiza_incarnata_aggr scrophularia_auriculata_aggr 0.9272434
#> 1958 dactylorhiza_incarnata_aggr epilobium_parviflorum 0.8684121
#> 1963 dactylorhiza_incarnata_aggr crepis_paludosa 0.8808559
#> 1982 dactylorhiza_incarnata_aggr cardamine_hirsuta 0.1752162
#> 1987 dactylorhiza_incarnata_aggr salix_pentandra 0.9587276
#> 1996 dactylorhiza_incarnata_aggr thalictrum_flavum 0.6831811
#> 1998 dactylorhiza_incarnata_aggr cirsium_arvense 0.4984696
#> 2001 silene_flos-cuculi_aggr epilobium_hirsutum 0.6373472
#> 2002 silene_flos-cuculi_aggr phragmites_australis_aggr 0.5382725
#> 2003 silene_flos-cuculi_aggr filipendula_ulmaria_aggr 0.8302874
#> 2004 silene_flos-cuculi_aggr eupatorium_cannabinum_aggr 0.7002306
#> 2005 silene_flos-cuculi_aggr juncus_subnodulosus 0.7457091
#> 2006 silene_flos-cuculi_aggr equisetum_palustre 0.7897131
#> 2007 silene_flos-cuculi_aggr galium_palustre_aggr 0.4946227
#> 2008 silene_flos-cuculi_aggr vicia_cracca_aggr 0.5318315
#> 2009 silene_flos-cuculi_aggr carex_acutiformis 0.6079667
#> 2010 silene_flos-cuculi_aggr valeriana_excelsa_aggr 0.6954145
#> 2011 silene_flos-cuculi_aggr mentha_aquatica_aggr 0.5134549
#> 2012 silene_flos-cuculi_aggr galium_uliginosum 0.8666927
#> 2013 silene_flos-cuculi_aggr cirsium_palustre 0.6640587
#> 2014 silene_flos-cuculi_aggr angelica_sylvestris_aggr 0.7757330
#> 2015 silene_flos-cuculi_aggr silene_flos-cuculi_aggr 1.0000000
#> 2023 silene_flos-cuculi_aggr scrophularia_auriculata_aggr 0.7659775
#> 2025 silene_flos-cuculi_aggr epilobium_parviflorum 0.6371126
#> 2030 silene_flos-cuculi_aggr crepis_paludosa 0.8184905
#> 2049 silene_flos-cuculi_aggr cardamine_hirsuta 0.1363161
#> 2054 silene_flos-cuculi_aggr salix_pentandra 0.7337836
#> 2063 silene_flos-cuculi_aggr thalictrum_flavum 0.4699902
#> 2065 silene_flos-cuculi_aggr cirsium_arvense 0.4815156
#> 2509 vicia_cracca_aggr carex_acutiformis 0.6464785
#> 2510 vicia_cracca_aggr valeriana_excelsa_aggr 0.5906447
#> 2511 vicia_cracca_aggr mentha_aquatica_aggr 0.4508547
#> 2512 vicia_cracca_aggr galium_uliginosum 0.5394910
#> 2513 vicia_cracca_aggr cirsium_palustre 0.7380829
#> 2514 vicia_cracca_aggr angelica_sylvestris_aggr 0.6445318
#> 2515 vicia_cracca_aggr silene_flos-cuculi_aggr 0.5318315
#> 2516 vicia_cracca_aggr equisetum_palustre 0.5558800
#> 2517 vicia_cracca_aggr filipendula_ulmaria_aggr 0.5835025
#> 2518 vicia_cracca_aggr phragmites_australis_aggr 0.6025329
#> 2519 vicia_cracca_aggr eupatorium_cannabinum_aggr 0.7783713
#> 2520 vicia_cracca_aggr epilobium_hirsutum 0.6309195
#> 2523 vicia_cracca_aggr scrophularia_auriculata_aggr 0.5809815
#> 2525 vicia_cracca_aggr epilobium_parviflorum 0.5916743
#> 2529 vicia_cracca_aggr galium_palustre_aggr 0.4233755
#> 2530 vicia_cracca_aggr crepis_paludosa 0.5643604
#> 2549 vicia_cracca_aggr cardamine_hirsuta 0.5433361
#> 2554 vicia_cracca_aggr salix_pentandra 0.5886729
#> 2563 vicia_cracca_aggr thalictrum_flavum 0.4286059
#> 2565 vicia_cracca_aggr cirsium_arvense 0.9238373
#> 2568 carex_acutiformis valeriana_excelsa_aggr 0.8995974
#> 2569 carex_acutiformis mentha_aquatica_aggr 0.7783723
#> 2570 carex_acutiformis galium_uliginosum 0.7109744
#> 2571 carex_acutiformis cirsium_palustre 0.8907189
#> 2572 carex_acutiformis angelica_sylvestris_aggr 0.8087321
#> 2573 carex_acutiformis silene_flos-cuculi_aggr 0.6079667
#> 2574 carex_acutiformis equisetum_palustre 0.7927488
#> 2575 carex_acutiformis filipendula_ulmaria_aggr 0.7484236
#> 2576 carex_acutiformis phragmites_australis_aggr 0.8730398
#> 2577 carex_acutiformis eupatorium_cannabinum_aggr 0.7965440
#> 2578 carex_acutiformis epilobium_hirsutum 0.9458175
#> 2581 carex_acutiformis scrophularia_auriculata_aggr 0.7795274
#> 2583 carex_acutiformis epilobium_parviflorum 0.9256430
#> 2584 carex_acutiformis carex_acutiformis 1.0000000
#> 2587 carex_acutiformis galium_palustre_aggr 0.7641250
#> 2588 carex_acutiformis crepis_paludosa 0.7327002
#> 2607 carex_acutiformis cardamine_hirsuta 0.2879957
#> 2612 carex_acutiformis salix_pentandra 0.8450804
#> 2621 carex_acutiformis thalictrum_flavum 0.7517246
#> 2623 carex_acutiformis cirsium_arvense 0.6045090
#> 3376 epilobium_parviflorum carex_acutiformis 0.9256430
#> 3377 epilobium_parviflorum angelica_sylvestris_aggr 0.8176661
#> 3378 epilobium_parviflorum silene_flos-cuculi_aggr 0.6371126
#> 3379 epilobium_parviflorum galium_palustre_aggr 0.7992094
#> 3380 epilobium_parviflorum crepis_paludosa 0.7605723
#> 3381 epilobium_parviflorum phragmites_australis_aggr 0.8553552
#> 3382 epilobium_parviflorum epilobium_hirsutum 0.9426363
#> 3384 epilobium_parviflorum equisetum_palustre 0.8275408
#> 3385 epilobium_parviflorum filipendula_ulmaria_aggr 0.7702339
#> 3386 epilobium_parviflorum eupatorium_cannabinum_aggr 0.7563185
#> 3387 epilobium_parviflorum valeriana_excelsa_aggr 0.9247706
#> 3389 epilobium_parviflorum galium_uliginosum 0.7450518
#> 3390 epilobium_parviflorum cirsium_palustre 0.8491798
#> 3399 epilobium_parviflorum cardamine_hirsuta 0.2193834
#> 3404 epilobium_parviflorum salix_pentandra 0.8522161
#> 3413 epilobium_parviflorum thalictrum_flavum 0.7842743
#> 3415 epilobium_parviflorum cirsium_arvense 0.5431549
#> 4108 cardamine_hirsuta phragmites_australis_aggr 0.2777306
#> 4109 cardamine_hirsuta epilobium_hirsutum 0.2453250
#> 4110 cardamine_hirsuta galium_uliginosum 0.1606385
#> 4111 cardamine_hirsuta carex_acutiformis 0.2879957
#> 4112 cardamine_hirsuta salix_pentandra 0.2047163
#> 4113 cardamine_hirsuta filipendula_ulmaria_aggr 0.1958168
#> 4114 cardamine_hirsuta galium_palustre_aggr 0.1403038
#> 4115 cardamine_hirsuta equisetum_palustre 0.1739213
#> 4116 cardamine_hirsuta cardamine_hirsuta 1.0000000
#> 4117 cardamine_hirsuta eupatorium_cannabinum_aggr 0.3515142
#> 4121 cardamine_hirsuta thalictrum_flavum 0.1799490
#> 4123 cardamine_hirsuta cirsium_arvense 0.6079280
#> 4125 cardamine_hirsuta valeriana_excelsa_aggr 0.2012222
#> 4188 salix_pentandra filipendula_ulmaria_aggr 0.8436914
#> 4189 salix_pentandra galium_palustre_aggr 0.6773638
#> 4190 salix_pentandra equisetum_palustre 0.9093252
#> 4191 salix_pentandra cardamine_hirsuta 0.2047163
#> 4192 salix_pentandra eupatorium_cannabinum_aggr 0.7987939
#> 4193 salix_pentandra phragmites_australis_aggr 0.7480951
#> 4195 salix_pentandra epilobium_hirsutum 0.8592023
#> 4196 salix_pentandra thalictrum_flavum 0.6654647
#> 4198 salix_pentandra cirsium_arvense 0.5372424
#> 4199 salix_pentandra carex_acutiformis 0.8450804
#> 4200 salix_pentandra valeriana_excelsa_aggr 0.9254020
#> 4269 thalictrum_flavum equisetum_palustre 0.6547658
#> 4270 thalictrum_flavum cirsium_arvense 0.3897361
#> 4271 thalictrum_flavum carex_acutiformis 0.7517246
#> 4272 thalictrum_flavum valeriana_excelsa_aggr 0.7351076
#> 4276 cirsium_arvense carex_acutiformis 0.6045090
#> 4277 cirsium_arvense valeriana_excelsa_aggr 0.5345743
#> N R L S GP SD tmax_sm
#> 1 0.7996330 0.8171038 0.7473396 0.7675077 0.7703748 0.8021662 0.7972977
#> 2 0.9107917 0.8400005 0.8390509 0.6908101 0.6919929 0.8254202 0.7605404
#> 3 0.6628017 0.9401096 0.7462454 0.8137153 0.8222921 0.8756849 0.8410428
#> 4 0.8807973 0.7505100 0.8461924 0.8400052 0.6769410 0.8289311 0.8010045
#> 5 0.9113708 0.8537513 0.8964523 0.8236139 0.7467285 0.7753285 0.7608998
#> 6 0.8549435 0.7739773 0.8503009 0.7375404 0.7541454 0.8687131 0.4063015
#> 7 0.7619153 0.7663878 0.8117581 0.7773048 0.8134332 0.9071872 0.8130709
#> 8 0.9511290 0.8013502 0.8336780 0.9513274 0.8152917 0.9730517 0.8272984
#> 9 0.9739150 0.9170120 0.9612541 0.9188424 0.9312584 0.9327206 0.8327299
#> 10 0.8154412 0.7691167 0.8987098 0.7064992 0.7234518 0.7309094 0.7818149
#> 11 0.7690783 0.7455919 0.8167604 0.7203610 0.8014434 0.8070981 0.7305856
#> 12 0.7979802 0.8247605 0.7910629 0.7253936 0.7630431 0.8190087 0.6387960
#> 13 0.6299135 0.7884486 0.7403687 0.9449696 0.8117179 0.9646360 0.8064188
#> 18 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000
#> 19 0.9100004 0.8508476 0.8838488 0.7847466 0.8391833 0.8889273 0.7724293
#> 21 0.7968412 0.9407306 0.8099729 0.9049500 0.8160098 0.9085409 0.9246264
#> 24 0.5352819 0.7002448 0.5590335 0.7835811 0.7370852 0.8715189 0.7692215
#> 25 0.7310913 0.6711173 0.7002390 0.6407120 0.5288406 0.6833411 0.8008550
#> 33 0.8106886 0.9146281 0.7647812 0.9588351 0.8422925 0.7632575 0.8848671
#> 34 0.9372325 0.9436876 0.9624611 0.9510594 0.8752891 0.9360711 0.9170599
#> 50 0.9488774 0.8804913 0.9005921 0.9196219 0.7926229 0.8584566 0.8623250
#> 74 0.7842405 0.8256992 0.8575105 0.8261453 0.8703876 0.5816147 0.9527392
#> 79 0.7270693 0.8812200 0.6281664 0.7263252 0.6512205 0.7179527 0.4917388
#> 88 0.8281877 0.7052285 0.7205150 0.6992656 0.6758053 0.7393928 0.7904655
#> 90 0.7988885 0.9401292 0.7720417 0.8321132 0.7503554 0.5857768 0.8812243
#> 93 0.7993171 0.8740329 0.8276242 0.4713939 0.6367317 0.8765377 0.8022784
#> 94 0.5818956 0.7892705 0.7437104 0.6424331 0.6820111 0.7097581 0.6400390
#> 95 0.6809970 0.7464756 0.7009550 0.6820099 0.7393695 0.8546877 0.8072827
#> 96 0.8513750 0.8153903 0.7385964 0.7574440 0.7385351 0.8941944 0.8360927
#> 97 0.7872437 0.7363099 0.7190989 0.5178901 0.6287018 0.7815592 0.4071748
#> 98 0.6209147 0.6919522 0.7537077 0.5718337 0.6365291 0.7179332 0.7404136
#> 99 0.7552948 0.7533103 0.8179034 0.7301109 0.7563523 0.8163388 0.7933130
#> 100 0.7954584 0.8197279 0.7372026 0.7116797 0.7189031 0.8139303 0.8001244
#> 101 0.6821759 0.7483837 0.7123492 0.5032980 0.5251420 0.8463120 0.6409871
#> 102 0.5986719 0.5994003 0.7347933 0.5545364 0.6412338 0.6377626 0.7300252
#> 103 0.7027554 0.8457333 0.6596648 0.5050230 0.5867700 0.7785325 0.6946614
#> 104 0.5967548 0.8006387 0.8357891 0.7270484 0.7437841 0.8195545 0.8296766
#> 106 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000
#> 109 0.7996330 0.8171038 0.7473396 0.7675077 0.7703748 0.8021662 0.7972977
#> 110 0.7178773 0.6949599 0.7359361 0.6017345 0.6485505 0.7208968 0.7055272
#> 112 0.7507709 0.8149323 0.8212511 0.7888571 0.7440330 0.8514127 0.7955060
#> 115 0.5084734 0.7273357 0.7566681 0.6596542 0.5696276 0.7436719 0.7549708
#> 116 0.5617098 0.5448446 0.6370582 0.4335519 0.4388299 0.6226120 0.7209833
#> 124 0.6619748 0.7847207 0.7978767 0.7579600 0.7358209 0.8124995 0.8535294
#> 125 0.7944907 0.8135220 0.7700421 0.7296027 0.7743164 0.7863107 0.7791778
#> 141 0.8122490 0.8635068 0.8089145 0.7000906 0.7187461 0.8553562 0.7621894
#> 165 0.7114734 0.7928909 0.6116567 0.8038941 0.7454125 0.7359052 0.7991260
#> 170 0.6158164 0.7056519 0.6393800 0.5825052 0.5192118 0.5795986 0.5150619
#> 179 0.8140588 0.8162663 0.8806860 0.5065749 0.5720155 0.8266142 0.6684412
#> 181 0.8054149 0.8635798 0.9098946 0.8928420 0.7634752 0.7266539 0.8931962
#> 184 0.7389936 0.8665105 0.7969796 0.7315792 0.7246837 0.7911895 0.6836532
#> 185 0.8498516 0.7790022 0.7872441 0.7539079 0.8835247 0.9609906 0.8950291
#> 186 0.9424005 0.8793286 0.8469450 0.6598148 0.8254518 0.9322509 0.8724445
#> 187 0.7844360 0.8029909 0.8241620 0.9416648 0.7894461 0.8894794 0.3924419
#> 188 0.8044846 0.7490239 0.8576542 0.8703177 0.7944466 0.7982449 0.8083747
#> 189 0.9091864 0.7788972 0.8408479 0.7194199 0.8342719 0.8369570 0.7355454
#> 190 0.9156540 0.8946100 0.8536680 0.7468312 0.7149631 0.8760299 0.8552385
#> 191 0.7468108 0.8034096 0.8513776 0.8275454 0.6884952 0.8932762 0.7307056
#> 192 0.7375143 0.6438535 0.8168427 0.7077219 0.8042431 0.6620290 0.8527899
#> 193 0.8687523 0.9530160 0.7178071 0.9366471 0.7655648 0.8932868 0.8670091
#> 194 0.6893256 0.8117276 0.7994437 0.7125494 0.7643987 0.8444081 0.8610939
#> 196 0.7993171 0.8740329 0.8276242 0.4713939 0.6367317 0.8765377 0.8022784
#> 198 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000
#> 199 0.9107917 0.8400005 0.8390509 0.6908101 0.6919929 0.8254202 0.7605404
#> 200 0.8476243 0.7399253 0.8770719 0.8017730 0.7529760 0.7931854 0.7544651
#> 202 0.7124142 0.8658690 0.8570269 0.6576322 0.8370619 0.9011629 0.8021633
#> 205 0.6136860 0.7581040 0.7122370 0.6853263 0.7953176 0.8582054 0.9187921
#> 206 0.7309871 0.6166171 0.7297183 0.9040646 0.7267427 0.7200987 0.8526122
#> 214 0.7976644 0.7794093 0.7552953 0.6800411 0.6557934 0.7865668 0.8254725
#> 215 0.8548945 0.8538971 0.8694157 0.7320261 0.7791078 0.8181005 0.7568119
#> 231 0.8818898 0.9501689 0.8949569 0.7665864 0.8776614 0.9416215 0.7664634
#> 255 0.7122020 0.8161078 0.7029167 0.5986094 0.6407715 0.6716358 0.7585783
#> 260 0.7795261 0.7932280 0.6994745 0.7056047 0.5559341 0.6596967 0.6404416
#> 269 0.8996051 0.8036907 0.8711026 0.8508671 0.9195261 0.9002020 0.7403269
#> 271 0.7287108 0.8973698 0.8712710 0.5622303 0.8473519 0.6375684 0.8579996
#> 274 0.6915141 0.7323123 0.6678227 0.9258170 0.7545585 0.8226936 0.7411255
#> 275 0.6910682 0.8831599 0.7186203 0.8769052 0.8433330 0.7576621 0.6935473
#> 276 0.5241386 0.7676512 0.6851376 0.7820103 0.9019920 0.8845694 0.3950422
#> 277 0.8603887 0.7612369 0.9163423 0.7202666 0.8782575 0.8792134 0.8104679
#> 278 0.6962768 0.7641487 0.8922744 0.7885468 0.7415082 0.8520418 0.7164458
#> 279 0.6651485 0.8999364 0.7722408 0.7661230 0.8576411 0.8515610 0.7493352
#> 280 0.5293207 0.8012994 0.7374908 0.8274725 0.8164589 0.7501571 0.8627504
#> 281 0.6667322 0.7497857 0.9114224 0.5600553 0.8114781 0.7713502 0.6814037
#> 282 0.8210432 0.8648003 0.6154225 0.7761610 0.8577585 0.8590016 0.5782661
#> 283 0.8828584 0.7601286 0.8517324 0.7833309 0.6997231 0.8408762 0.6763175
#> 284 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000
#> 285 0.5818956 0.7892705 0.7437104 0.6424331 0.6820111 0.7097581 0.6400390
#> 287 0.7389936 0.8665105 0.7969796 0.7315792 0.7246837 0.7911895 0.6836532
#> 288 0.6628017 0.9401096 0.7462454 0.8137153 0.8222921 0.8756849 0.8410428
#> 289 0.6475608 0.8522725 0.8473559 0.6589186 0.8413912 0.8439790 0.7809196
#> 291 0.4667143 0.9098388 0.9021156 0.8487468 0.8001043 0.8322390 0.8246720
#> 294 0.8208723 0.7291558 0.6991920 0.9180935 0.7883231 0.8848951 0.7103754
#> 295 0.7910839 0.6910834 0.8752354 0.6653140 0.5674695 0.6607453 0.7564603
#> 303 0.8083141 0.8746666 0.8642341 0.7803513 0.7026805 0.6437850 0.7352075
#> 304 0.6018012 0.9094187 0.7731067 0.8394750 0.8545543 0.9154368 0.8177246
#> 320 0.6217778 0.8916171 0.7441404 0.8305178 0.7851108 0.8210757 0.8015314
#> 344 0.5147124 0.7939254 0.6515340 0.8253719 0.7388945 0.4952044 0.8313725
#> 349 0.8945886 0.9099219 0.8703281 0.9026490 0.7768020 0.8388203 0.5010268
#> 358 0.7091062 0.7283939 0.7465107 0.8020062 0.7101916 0.6997917 0.8435032
#> 360 0.4715542 0.9192793 0.8119706 0.7488362 0.6946902 0.4907394 0.7372191
#> 363 0.8045282 0.6638160 0.9247541 0.9016169 0.8709553 0.9195170 0.9277009
#> 364 0.7897298 0.9450974 0.9567741 0.8036644 0.7717502 0.9085034 0.4075620
#> 365 0.8216432 0.8812071 0.7321705 0.7582495 0.7448543 0.8097815 0.8484025
#> 366 0.9217432 0.9018216 0.7291352 0.8260613 0.7915168 0.8354639 0.7382950
#> 367 0.8808033 0.8205047 0.8444235 0.8158156 0.6887722 0.8833524 0.8882241
#> 368 0.8329601 0.5856333 0.8726790 0.8187458 0.6260682 0.8891194 0.7745518
#> 369 0.8370021 0.6450306 0.7110503 0.6022696 0.7351765 0.6645087 0.8409315
#> 370 0.7709068 0.7600194 0.8976697 0.7956231 0.7041611 0.9202271 0.7797517
#> 371 0.6128080 0.9392016 0.6657992 0.8135852 0.7190600 0.8458583 0.8546605
#> 372 0.6915141 0.7323123 0.6678227 0.9258170 0.7545585 0.8226936 0.7411255
#> 373 0.6809970 0.7464756 0.7009550 0.6820099 0.7393695 0.8546877 0.8072827
#> 375 0.8498516 0.7790022 0.7872441 0.7539079 0.8835247 0.9609906 0.8950291
#> 376 0.8807973 0.7505100 0.8461924 0.8400052 0.6769410 0.8289311 0.8010045
#> 377 0.9280119 0.7340446 0.7815458 0.7044426 0.6966695 0.8005836 0.7863965
#> 378 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000
#> 379 0.7331881 0.8050440 0.7158390 0.8894346 0.8314462 0.8920476 0.8565914
#> 382 0.5405571 0.5374791 0.5291019 0.9033382 0.7091118 0.8762565 0.8953569
#> 383 0.8229079 0.6203694 0.6063674 0.6926046 0.6292379 0.7270578 0.9040652
#> 391 0.8390816 0.7484916 0.6641822 0.8073170 0.6229594 0.7738022 0.8373360
#> 392 0.8464513 0.8035125 0.8586486 0.8682101 0.7816271 0.8316865 0.7741434
#> 408 0.8517078 0.8125977 0.8746544 0.8725452 0.8306379 0.9633677 0.7875392
#> 432 0.7566309 0.8980779 0.7894750 0.8415068 0.6178041 0.6447505 0.8175159
#> 437 0.7686302 0.6982829 0.5631986 0.8839926 0.5790493 0.6808308 0.5998148
#> 446 0.7584430 0.6043829 0.6824482 0.8176999 0.8062585 0.8744524 0.8142613
#> 448 0.7138102 0.7789055 0.6968881 0.7865914 0.8762682 0.6097884 0.8939711
#> 451 0.8041418 0.6971020 0.9432407 0.7084436 0.8584981 0.8351745 0.3899415
#> 452 0.7499036 0.6623648 0.7845540 0.6853746 0.8401267 0.7508032 0.7938234
#> 453 0.8746979 0.6853377 0.7736801 0.7751858 0.8550854 0.7875303 0.7068888
#> 454 0.9174510 0.8221081 0.9016251 0.7574815 0.7669912 0.8238231 0.8357020
#> 455 0.7511426 0.9126483 0.9327310 0.7238476 0.7025128 0.9352189 0.7096634
#> 456 0.6986943 0.6620080 0.7554754 0.5512695 0.8235119 0.6215193 0.8018528
#> 457 0.8141981 0.8976677 0.8284585 0.6998371 0.7817497 0.8409026 0.7516098
#> 458 0.6644342 0.6956469 0.7068132 0.7696318 0.7802521 0.7921522 0.8258591
#> 459 0.6910682 0.8831599 0.7186203 0.8769052 0.8433330 0.7576621 0.6935473
#> 460 0.8513750 0.8153903 0.7385964 0.7574440 0.7385351 0.8941944 0.8360927
#> 462 0.9424005 0.8793286 0.8469450 0.6598148 0.8254518 0.9322509 0.8724445
#> 463 0.9113708 0.8537513 0.8964523 0.8236139 0.7467285 0.7753285 0.7608998
#> 464 0.8317198 0.7394180 0.8369703 0.6436174 0.7831672 0.7433854 0.7346995
#> 465 0.8045282 0.6638160 0.9247541 0.9016169 0.8709553 0.9195170 0.9277009
#> 466 0.7369172 0.8211385 0.7669919 0.9164297 0.9179628 0.8572800 0.8057234
#> 469 0.5783124 0.8459330 0.5729704 0.9022102 0.7814315 0.7991135 0.8475230
#> 470 0.6776835 0.5889900 0.6524823 0.6042298 0.6340002 0.6732079 0.8386350
#> 478 0.7579439 0.7868144 0.6956927 0.7894927 0.6854352 0.7602367 0.8006712
#> 479 0.8707308 0.8106133 0.9144315 0.8128877 0.8632691 0.7769313 0.7355522
#> 481 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000
#> 495 0.9057857 0.8431393 0.9294027 0.7959772 0.8999178 0.8935299 0.7442278
#> 519 0.7217971 0.7146110 0.8190004 0.9202934 0.6794673 0.7240706 0.7762491
#> 524 0.7318702 0.8168035 0.6073202 0.8229397 0.6487223 0.6222980 0.5701325
#> 533 0.9007166 0.8073560 0.7335474 0.7196307 0.7731614 0.9193016 0.7563838
#> 535 0.7736559 0.8539903 0.7399710 0.8629433 0.8175118 0.6789222 0.8748478
#> 538 0.6301737 0.9065074 0.7514956 0.8894010 0.9025991 0.8504178 0.4836015
#> 539 0.8130246 0.9161718 0.7389608 0.7629483 0.7593725 0.8659543 0.5162761
#> 540 0.8586701 0.8509912 0.8536120 0.7892905 0.7934823 0.9012866 0.4709413
#> 541 0.8782781 0.6187505 0.9056025 0.8612628 0.8264558 0.8358328 0.4419733
#> 542 0.7315246 0.6665360 0.7227662 0.6958190 0.8468013 0.7070546 0.4526813
#> 543 0.6559724 0.7790373 0.8599613 0.9811177 0.8878161 0.9363980 0.3762589
#> 544 0.4937352 0.9344261 0.6839106 0.7536368 0.7299146 0.8697104 0.4625415
#> 545 0.5241386 0.7676512 0.6851376 0.7820103 0.9019920 0.8845694 0.3950422
#> 546 0.7872437 0.7363099 0.7190989 0.5178901 0.6287018 0.7815592 0.4071748
#> 548 0.7844360 0.8029909 0.8241620 0.9416648 0.7894461 0.8894794 0.3924419
#> 549 0.8549435 0.7739773 0.8503009 0.7375404 0.7541454 0.8687131 0.4063015
#> 550 0.8500020 0.7569584 0.7962955 0.8039448 0.8263572 0.8263728 0.5247749
#> 551 0.7897298 0.9450974 0.9567741 0.8036644 0.7717502 0.9085034 0.4075620
#> 552 0.9076540 0.8319490 0.7348088 0.7062610 0.8135048 0.8816207 0.4622165
#> 553 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000
#> 555 0.3983303 0.5658111 0.5593209 0.7359729 0.8591770 0.9478568 0.4080082
#> 556 0.6289706 0.6511699 0.6319350 0.8697677 0.6485905 0.7381761 0.3854359
#> 564 0.6668542 0.7696947 0.6682990 0.7250665 0.6835603 0.7147306 0.4750296
#> 565 0.9137641 0.8294239 0.8691601 0.7806549 0.8287695 0.8916775 0.4597642
#> 567 0.8041418 0.6971020 0.9432407 0.7084436 0.8584981 0.8351745 0.3899415
#> 581 0.8963388 0.8305743 0.8990000 0.8152151 0.8080619 0.9086057 0.5037498
#> 605 0.7829215 0.9076337 0.7832022 0.6472381 0.6680316 0.5703209 0.4218827
#> 610 0.6069394 0.7415713 0.5954225 0.7517913 0.7400904 0.7615621 0.5593744
#> 619 0.7102381 0.6167201 0.7214813 0.8843844 0.7902330 0.8108347 0.3690114
#> 621 0.9186954 0.8022444 0.7164092 0.6092826 0.7004986 0.5485188 0.4340778
#> 624 0.8034823 0.9350062 0.9219160 0.8110216 0.8083309 0.9010672 0.8513641
#> 625 0.7659811 0.8239177 0.8410835 0.8528228 0.8679829 0.8941921 0.9114178
#> 626 0.6564395 0.5813196 0.8103527 0.7593636 0.8303123 0.7077970 0.8608052
#> 627 0.7845816 0.7282186 0.9400516 0.8064179 0.9254042 0.8238521 0.8557110
#> 628 0.8458839 0.7250953 0.6712336 0.8734595 0.9141921 0.8024028 0.7466320
#> 629 0.7535735 0.8622568 0.8321091 0.8043093 0.7793845 0.8927741 0.8402583
#> 630 0.8603887 0.7612369 0.9163423 0.7202666 0.8782575 0.8792134 0.8104679
#> 631 0.6209147 0.6919522 0.7537077 0.5718337 0.6365291 0.7179332 0.7404136
#> 633 0.8044846 0.7490239 0.8576542 0.8703177 0.7944466 0.7982449 0.8083747
#> 634 0.7619153 0.7663878 0.8117581 0.7773048 0.8134332 0.9071872 0.8130709
#> 635 0.7680641 0.7842939 0.9219581 0.9120535 0.9176153 0.9422639 0.9310280
#> 636 0.8216432 0.8812071 0.7321705 0.7582495 0.7448543 0.8097815 0.8484025
#> 637 0.5760334 0.8169870 0.9170053 0.7394589 0.8530305 0.8494371 0.8576318
#> 638 0.6301737 0.9065074 0.7514956 0.8894010 0.9025991 0.8504178 0.4836015
#> 640 0.6979180 0.5176448 0.6702421 0.6617428 0.8971858 0.8759023 0.8537823
#> 641 0.8994721 0.7040144 0.8377249 0.8563200 0.6716421 0.7559523 0.8626347
#> 649 0.9144185 0.7698143 0.8220121 0.7749258 0.7593515 0.7076195 0.8725702
#> 650 0.7040182 0.8192466 0.8367052 0.8061557 0.8592095 0.8643940 0.8916319
#> 652 0.7499036 0.6623648 0.7845540 0.6853746 0.8401267 0.7508032 0.7938234
#> 653 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000
#> 666 0.7236259 0.7862493 0.8070550 0.8434387 0.8522650 0.8303033 0.9227739
#> 690 0.6381953 0.8963398 0.7253519 0.6787163 0.7402729 0.5387100 0.7947758
#> 695 0.9033655 0.7264421 0.7973256 0.6645244 0.6703056 0.7447718 0.6539523
#> 704 0.7341652 0.5665608 0.7797369 0.7934516 0.8048966 0.7205396 0.8221927
#> 706 0.5668466 0.7641572 0.8200497 0.6542304 0.7475937 0.5290088 0.8216121
#> 709 0.9448668 0.8609191 0.8329320 0.9450957 0.8292091 0.9390170 0.8313250
#> 710 0.8059899 0.6026293 0.7825351 0.7086993 0.6464037 0.7388748 0.7627802
#> 711 0.8030090 0.7091226 0.9142656 0.7602414 0.8565025 0.7953399 0.7813661
#> 712 0.8151647 0.7513624 0.6868013 0.7488363 0.7319151 0.8165478 0.6958229
#> 713 0.6530574 0.9078742 0.8943550 0.9836750 0.9175095 0.9769230 0.8502231
#> 714 0.6962768 0.7641487 0.8922744 0.7885468 0.7415082 0.8520418 0.7164458
#> 715 0.7552948 0.7533103 0.8179034 0.7301109 0.7563523 0.8163388 0.7933130
#> 717 0.9091864 0.7788972 0.8408479 0.7194199 0.8342719 0.8369570 0.7355454
#> 718 0.9511290 0.8013502 0.8336780 0.9513274 0.8152917 0.9730517 0.8272984
#> 719 0.9196313 0.7799413 0.8845965 0.8153311 0.8140074 0.8887221 0.8688491
#> 720 0.9217432 0.9018216 0.7291352 0.8260613 0.7915168 0.8354639 0.7382950
#> 721 0.7690124 0.8535855 0.9449386 0.8566743 0.9233247 0.9143834 0.8273100
#> 722 0.8130246 0.9161718 0.7389608 0.7629483 0.7593725 0.8659543 0.5162761
#> 724 0.5610095 0.5461614 0.6816216 0.7436463 0.7689088 0.8624107 0.7495270
#> 725 0.7752997 0.6677967 0.8101452 0.6744288 0.6603008 0.6983289 0.7310586
#> 733 0.8477743 0.7996865 0.8910093 0.9596027 0.8138266 0.7862683 0.8998671
#> 734 0.8980644 0.8538344 0.8477900 0.9484161 0.8854610 0.9192818 0.8908353
#> 736 0.8746979 0.6853377 0.7736801 0.7751858 0.8550854 0.7875303 0.7068888
#> 737 0.8034823 0.9350062 0.9219160 0.8110216 0.8083309 0.9010672 0.8513641
#> 738 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000
#> 750 0.9075046 0.8239667 0.8102703 0.9268093 0.9246501 0.8627396 0.9080293
#> 774 0.7704494 0.9496625 0.7301363 0.7777904 0.8011952 0.6081485 0.8077047
#> 779 0.7620724 0.7121223 0.7709082 0.7137777 0.5274447 0.6946596 0.6394337
#> 788 0.8251105 0.5963460 0.7842985 0.6922481 0.7793183 0.7554566 0.7228522
#> 790 0.7565360 0.8208302 0.8848860 0.7870268 0.9037800 0.6109495 0.8231811
#> 793 0.8189195 0.7402193 0.9082036 0.7364731 0.7907812 0.7772183 0.7797690
#> 794 0.7636954 0.7236053 0.8357705 0.7836491 0.8388832 0.7664411 0.8963105
#> 795 0.7971523 0.8721568 0.7803624 0.7751784 0.8290115 0.8680874 0.7902185
#> 796 0.6274695 0.8576097 0.7350321 0.9321906 0.7903267 0.9455849 0.9218045
#> 797 0.6651485 0.8999364 0.7722408 0.7661230 0.8576411 0.8515610 0.7493352
#> 798 0.7954584 0.8197279 0.7372026 0.7116797 0.7189031 0.8139303 0.8001244
#> 800 0.9156540 0.8946100 0.8536680 0.7468312 0.7149631 0.8760299 0.8552385
#> 801 0.9739150 0.9170120 0.9612541 0.9188424 0.9312584 0.9327206 0.8327299
#> 802 0.9112713 0.8298478 0.9142997 0.8659041 0.9031611 0.8996033 0.8742363
#> 803 0.8808033 0.8205047 0.8444235 0.8158156 0.6887722 0.8833524 0.8882241
#> 804 0.7901791 0.9605783 0.8154372 0.8390344 0.8406933 0.9223693 0.8944652
#> 805 0.8586701 0.8509912 0.8536120 0.7892905 0.7934823 0.9012866 0.4709413
#> 806 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000
#> 807 0.5379757 0.6797362 0.5702556 0.7223069 0.7964753 0.9079677 0.8950648
#> 808 0.7339762 0.6758586 0.7156221 0.7147587 0.5725543 0.7397914 0.8789146
#> 816 0.8031485 0.8586382 0.7543570 0.9207710 0.8244946 0.7867896 0.9154337
#> 817 0.9310776 0.9452853 0.9655906 0.9258442 0.8989086 0.8983337 0.8662678
#> 819 0.9174510 0.8221081 0.9016251 0.7574815 0.7669912 0.8238231 0.8357020
#> 820 0.7659811 0.8239177 0.8410835 0.8528228 0.8679829 0.8941921 0.9114178
#> 821 0.9448668 0.8609191 0.8329320 0.9450957 0.8292091 0.9390170 0.8313250
#> 833 0.9554305 0.9443506 0.9036043 0.9282397 0.8180109 0.9123169 0.8874272
#> 857 0.7636084 0.8883164 0.8465650 0.7624335 0.8461650 0.6120104 0.8140087
#> 862 0.7353960 0.8384863 0.6523444 0.7078593 0.6738455 0.6932886 0.6344508
#> 871 0.8262737 0.7029639 0.7298504 0.7210194 0.7044925 0.7931948 0.7544187
#> 873 0.8004657 0.9341769 0.7661397 0.7735754 0.7705581 0.5965582 0.8784854
#> 876 0.7623723 0.5815219 0.7844926 0.5728020 0.7613027 0.5792404 0.7177651
#> 877 0.6337115 0.8238773 0.7905229 0.8736738 0.9122592 0.8654137 0.6531275
#> 878 0.4696344 0.6178841 0.6960968 0.6964207 0.6121049 0.7449500 0.7026996
#> 879 0.5293207 0.8012994 0.7374908 0.8274725 0.8164589 0.7501571 0.8627504
#> 880 0.6821759 0.7483837 0.7123492 0.5032980 0.5251420 0.8463120 0.6409871
#> 882 0.7468108 0.8034096 0.8513776 0.8275454 0.6884952 0.8932762 0.7307056
#> 883 0.8154412 0.7691167 0.8987098 0.7064992 0.7234518 0.7309094 0.7818149
#> 884 0.8761868 0.6568186 0.8641419 0.6776743 0.8283866 0.6946447 0.8319416
#> 885 0.8329601 0.5856333 0.8726790 0.8187458 0.6260682 0.8891194 0.7745518
#> 886 0.8786891 0.7377088 0.7664826 0.7138343 0.6967465 0.8125614 0.8311695
#> 887 0.8782781 0.6187505 0.9056025 0.8612628 0.8264558 0.8358328 0.4419733
#> 888 0.8189195 0.7402193 0.9082036 0.7364731 0.7907812 0.7772183 0.7797690
#> 889 0.3816625 0.9185458 0.5682286 0.8004999 0.8592785 0.7956259 0.7859797
#> 890 0.6571767 0.5089568 0.7012753 0.7724170 0.6449347 0.6535390 0.8454285
#> 898 0.6825285 0.7004225 0.7012081 0.6831498 0.6637352 0.6979970 0.7646989
#> 899 0.8686766 0.7268353 0.9218051 0.7505882 0.7376643 0.7490540 0.8101974
#> 901 0.7511426 0.9126483 0.9327310 0.7238476 0.7025128 0.9352189 0.7096634
#> 902 0.6564395 0.5813196 0.8103527 0.7593636 0.8303123 0.7077970 0.8608052
#> 903 0.8059899 0.6026293 0.7825351 0.7086993 0.6464037 0.7388748 0.7627802
#> 913 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000
#> 915 0.8391321 0.7626734 0.8812347 0.7812911 0.6901025 0.8562857 0.8421134
#> 939 0.8007397 0.6320732 0.8165083 0.6662122 0.6848082 0.6750572 0.7731191
#> 944 0.6112540 0.7404034 0.6636693 0.8524564 0.7891384 0.6777443 0.6116588
#> 953 0.6675367 0.8004051 0.7379283 0.9008264 0.7128429 0.8970285 0.9162278
#> 955 0.8400984 0.7700196 0.7288510 0.6065604 0.5896889 0.6282854 0.7425446
#> 958 0.6961245 0.6401479 0.6636027 0.6804127 0.8448682 0.6550607 0.8647032
#> 959 0.6045449 0.6431801 0.8281795 0.7558299 0.8350046 0.7838330 0.9000401
#> 960 0.6667322 0.7497857 0.9114224 0.5600553 0.8114781 0.7713502 0.6814037
#> 961 0.5986719 0.5994003 0.7347933 0.5545364 0.6412338 0.6377626 0.7300252
#> 963 0.7375143 0.6438535 0.8168427 0.7077219 0.8042431 0.6620290 0.8527899
#> 964 0.7690783 0.7455919 0.8167604 0.7203610 0.8014434 0.8070981 0.7305856
#> 965 0.8340079 0.8822389 0.9002092 0.8858619 0.9137743 0.7888970 0.8459612
#> 966 0.8370021 0.6450306 0.7110503 0.6022696 0.7351765 0.6645087 0.8409315
#> 967 0.6723018 0.7447309 0.8931066 0.6325292 0.8615250 0.7421847 0.7920589
#> 968 0.7315246 0.6665360 0.7227662 0.6958190 0.8468013 0.7070546 0.4526813
#> 969 0.7636954 0.7236053 0.8357705 0.7836491 0.8388832 0.7664411 0.8963105
#> 970 0.4898191 0.5132563 0.6395866 0.5108928 0.8954081 0.7188042 0.9044716
#> 971 0.8591389 0.9000417 0.8701923 0.7480142 0.7177155 0.6020357 0.8380862
#> 979 0.8395322 0.8063664 0.8613899 0.7449377 0.7908729 0.5878352 0.8355703
#> 980 0.7553981 0.7540461 0.8301065 0.7139660 0.8371819 0.8040770 0.7704522
#> 982 0.6986943 0.6620080 0.7554754 0.5512695 0.8235119 0.6215193 0.8018528
#> 983 0.7845816 0.7282186 0.9400516 0.8064179 0.9254042 0.8238521 0.8557110
#> 984 0.8030090 0.7091226 0.9142656 0.7602414 0.8565025 0.7953399 0.7813661
#> 994 0.7623723 0.5815219 0.7844926 0.5728020 0.7613027 0.5792404 0.7177651
#> 996 0.7390667 0.6796027 0.7835683 0.7249827 0.8822629 0.6957042 0.8080070
#> 1020 0.7899241 0.6916226 0.7323325 0.5611195 0.7652039 0.4499690 0.7193758
#> 1025 0.7566470 0.7874489 0.7999635 0.4966872 0.5980400 0.7386320 0.7274859
#> 1034 0.6707090 0.5170290 0.7396251 0.6062115 0.8255878 0.5827996 0.6876680
#> 1036 0.6582600 0.7053394 0.8009567 0.5850366 0.7896996 0.4663484 0.7928025
#> 1039 0.7695792 0.7884079 0.6251155 0.7395337 0.6984966 0.8315334 0.8257984
#> 1040 0.8210432 0.8648003 0.6154225 0.7761610 0.8577585 0.8590016 0.5782661
#> 1041 0.7027554 0.8457333 0.6596648 0.5050230 0.5867700 0.7785325 0.6946614
#> 1043 0.8687523 0.9530160 0.7178071 0.9366471 0.7655648 0.8932868 0.8670091
#> 1044 0.7979802 0.8247605 0.7910629 0.7253936 0.7630431 0.8190087 0.6387960
#> 1045 0.7404656 0.7325141 0.7177600 0.7863709 0.8994533 0.7888917 0.7303285
#> 1046 0.7709068 0.7600194 0.8976697 0.7956231 0.7041611 0.9202271 0.7797517
#> 1047 0.5973311 0.8505207 0.6577268 0.6976545 0.7811594 0.8636424 0.6900575
#> 1048 0.6559724 0.7790373 0.8599613 0.9811177 0.8878161 0.9363980 0.3762589
#> 1049 0.7971523 0.8721568 0.7803624 0.7751784 0.8290115 0.8680874 0.7902185
#> 1050 0.7343709 0.7765344 0.4813338 0.7351980 0.9103578 0.9148416 0.8438249
#> 1051 0.7604320 0.6153391 0.5633833 0.8663615 0.6764906 0.7330092 0.7777399
#> 1059 0.8193722 0.7629272 0.6433692 0.7121566 0.7166667 0.7075828 0.7427822
#> 1060 0.7361554 0.8345240 0.7929781 0.7711407 0.8108712 0.8375419 0.6754297
#> 1062 0.8141981 0.8976677 0.8284585 0.6998371 0.7817497 0.8409026 0.7516098
#> 1063 0.8458839 0.7250953 0.6712336 0.8734595 0.9141921 0.8024028 0.7466320
#> 1064 0.8151647 0.7513624 0.6868013 0.7488363 0.7319151 0.8165478 0.6958229
#> 1074 0.6337115 0.8238773 0.7905229 0.8736738 0.9122592 0.8654137 0.6531275
#> 1076 0.7528950 0.9243339 0.7971816 0.8044205 0.7749197 0.9136455 0.7044920
#> 1081 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000
#> 1100 0.6035807 0.7905873 0.7363823 0.6386317 0.7207332 0.5649776 0.6274256
#> 1105 0.8087118 0.7957007 0.5170727 0.7540095 0.7340697 0.7536590 0.6780817
#> 1114 0.8597394 0.8179709 0.6264038 0.8855459 0.7764423 0.8191430 0.6276898
#> 1116 0.6011047 0.8810713 0.6528215 0.5981180 0.6733229 0.5343050 0.7349717
#> 1119 0.8828584 0.7601286 0.8517324 0.7833309 0.6997231 0.8408762 0.6763175
#> 1120 0.5967548 0.8006387 0.8357891 0.7270484 0.7437841 0.8195545 0.8296766
#> 1121 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000
#> 1122 0.6893256 0.8117276 0.7994437 0.7125494 0.7643987 0.8444081 0.8610939
#> 1123 0.6299135 0.7884486 0.7403687 0.9449696 0.8117179 0.9646360 0.8064188
#> 1124 0.5923411 0.7394147 0.7802163 0.8070928 0.7815358 0.8874809 0.8285113
#> 1125 0.6128080 0.9392016 0.6657992 0.8135852 0.7190600 0.8458583 0.8546605
#> 1126 0.4305601 0.8435176 0.8923620 0.8510928 0.8478001 0.9180084 0.8410228
#> 1127 0.4937352 0.9344261 0.6839106 0.7536368 0.7299146 0.8697104 0.4625415
#> 1128 0.6274695 0.8576097 0.7350321 0.9321906 0.7903267 0.9455849 0.9218045
#> 1129 0.8619887 0.5742408 0.7701467 0.7390520 0.7425843 0.8646797 0.8735452
#> 1130 0.6896067 0.5986246 0.7338842 0.6681013 0.6866789 0.6973603 0.8260390
#> 1138 0.7391829 0.7784419 0.9155118 0.9648798 0.8834554 0.7899796 0.9135306
#> 1139 0.5683304 0.8418028 0.7570624 0.9432382 0.8263395 0.9151812 0.8451208
#> 1141 0.6644342 0.6956469 0.7068132 0.7696318 0.7802521 0.7921522 0.8258591
#> 1142 0.7535735 0.8622568 0.8321091 0.8043093 0.7793845 0.8927741 0.8402583
#> 1143 0.6530574 0.9078742 0.8943550 0.9836750 0.9175095 0.9769230 0.8502231
#> 1153 0.4696344 0.6178841 0.6960968 0.6964207 0.6121049 0.7449500 0.7026996
#> 1155 0.5898370 0.8495940 0.7612966 0.9142505 0.8540460 0.8737772 0.8587120
#> 1160 0.7695792 0.7884079 0.6251155 0.7395337 0.6984966 0.8315334 0.8257984
#> 1179 0.4650252 0.9229107 0.6260452 0.7719063 0.8293114 0.6076794 0.7967984
#> 1184 0.8216795 0.7064261 0.7664527 0.7009664 0.4784430 0.6851528 0.6496518
#> 1193 0.7047089 0.6540829 0.7717665 0.6791524 0.7401502 0.7611451 0.6823518
#> 1195 0.4508150 0.8174857 0.9152418 0.7819298 0.8299650 0.6073275 0.8879848
#> 1578 0.9280119 0.7340446 0.7815458 0.7044426 0.6966695 0.8005836 0.7863965
#> 1579 0.8044498 0.8527799 0.8757129 0.7246652 0.8347745 0.8392861 0.8191554
#> 1580 0.8500020 0.7569584 0.7962955 0.8039448 0.8263572 0.8263728 0.5247749
#> 1581 0.9112713 0.8298478 0.9142997 0.8659041 0.9031611 0.8996033 0.8742363
#> 1582 0.5014092 0.5869081 0.6232907 0.6103805 0.8901857 0.8597474 0.7987537
#> 1583 0.7577440 0.8093993 0.7880737 0.7878107 0.6579302 0.7851849 0.8007699
#> 1585 0.7178773 0.6949599 0.7359361 0.6017345 0.6485505 0.7208968 0.7055272
#> 1586 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000
#> 1587 0.9100004 0.8508476 0.8838488 0.7847466 0.8391833 0.8889273 0.7724293
#> 1588 0.6475608 0.8522725 0.8473559 0.6589186 0.8413912 0.8439790 0.7809196
#> 1589 0.8476243 0.7399253 0.8770719 0.8017730 0.7529760 0.7931854 0.7544651
#> 1591 0.7998028 0.9016114 0.7927039 0.7880021 0.8139423 0.7402485 0.8366852
#> 1592 0.9073102 0.8627472 0.9023486 0.8074219 0.8532146 0.8433871 0.8553694
#> 1594 0.8317198 0.7394180 0.8369703 0.6436174 0.7831672 0.7433854 0.7346995
#> 1595 0.7680641 0.7842939 0.9219581 0.9120535 0.9176153 0.9422639 0.9310280
#> 1596 0.9196313 0.7799413 0.8845965 0.8153311 0.8140074 0.8887221 0.8688491
#> 1606 0.8761868 0.6568186 0.8641419 0.6776743 0.8283866 0.6946447 0.8319416
#> 1608 0.8924499 0.7831593 0.8535575 0.8265862 0.8383720 0.8265907 0.9078400
#> 1613 0.7404656 0.7325141 0.7177600 0.7863709 0.8994533 0.7888917 0.7303285
#> 1632 0.7931904 0.7754686 0.7989653 0.6510284 0.8038818 0.5547366 0.7577538
#> 1637 0.7216594 0.8841878 0.7310757 0.6011360 0.6592371 0.6977111 0.6790087
#> 1646 0.7594881 0.6023781 0.7562763 0.7169604 0.7598980 0.7179495 0.7845816
#> 1648 0.7855624 0.8117320 0.7965870 0.6637614 0.7501467 0.5400579 0.7786243
#> 1723 0.9076540 0.8319490 0.7348088 0.7062610 0.8135048 0.8816207 0.4622165
#> 1724 0.7901791 0.9605783 0.8154372 0.8390344 0.8406933 0.9223693 0.8944652
#> 1725 0.3324278 0.6692782 0.7152640 0.8381468 0.7880692 0.8552232 0.8278789
#> 1726 0.5634970 0.6932667 0.8020038 0.6028661 0.6353235 0.6704315 0.8589832
#> 1727 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000
#> 1728 0.7507709 0.8149323 0.8212511 0.7888571 0.7440330 0.8514127 0.7955060
#> 1729 0.8044498 0.8527799 0.8757129 0.7246652 0.8347745 0.8392861 0.8191554
#> 1730 0.7968412 0.9407306 0.8099729 0.9049500 0.8160098 0.9085409 0.9246264
#> 1731 0.4667143 0.9098388 0.9021156 0.8487468 0.8001043 0.8322390 0.8246720
#> 1732 0.7124142 0.8658690 0.8570269 0.6576322 0.8370619 0.9011629 0.8021633
#> 1733 0.7331881 0.8050440 0.7158390 0.8894346 0.8314462 0.8920476 0.8565914
#> 1734 0.6204750 0.8905856 0.8454009 0.8718080 0.7490167 0.7732024 0.9029751
#> 1735 0.8569288 0.9812481 0.8269443 0.8926661 0.9191955 0.8957204 0.8990204
#> 1737 0.7369172 0.8211385 0.7669919 0.9164297 0.9179628 0.8572800 0.8057234
#> 1738 0.5760334 0.8169870 0.9170053 0.7394589 0.8530305 0.8494371 0.8576318
#> 1739 0.7690124 0.8535855 0.9449386 0.8566743 0.9233247 0.9143834 0.8273100
#> 1749 0.8786891 0.7377088 0.7664826 0.7138343 0.6967465 0.8125614 0.8311695
#> 1751 0.8224957 0.9125546 0.8132751 0.8702896 0.9540080 0.9145321 0.9043968
#> 1756 0.5973311 0.8505207 0.6577268 0.6976545 0.7811594 0.8636424 0.6900575
#> 1775 0.8319700 0.8768958 0.7094888 0.9191518 0.7465004 0.6490593 0.9129162
#> 1780 0.5364543 0.8543410 0.7798650 0.7753778 0.5908455 0.6844365 0.5389026
#> 1789 0.6478512 0.6884680 0.8031257 0.7146027 0.7800816 0.8190661 0.8299167
#> 1791 0.9269535 0.9339291 0.8905998 0.8927261 0.8851430 0.6407917 0.9008417
#> 1933 0.6159399 0.4411697 0.6006251 0.6504425 0.7550690 0.7638620 0.9157207
#> 1934 0.3324278 0.6692782 0.7152640 0.8381468 0.7880692 0.8552232 0.8278789
#> 1935 0.5084734 0.7273357 0.7566681 0.6596542 0.5696276 0.7436719 0.7549708
#> 1936 0.5014092 0.5869081 0.6232907 0.6103805 0.8901857 0.8597474 0.7987537
#> 1937 0.5352819 0.7002448 0.5590335 0.7835811 0.7370852 0.8715189 0.7692215
#> 1938 0.8208723 0.7291558 0.6991920 0.9180935 0.7883231 0.8848951 0.7103754
#> 1939 0.6136860 0.7581040 0.7122370 0.6853263 0.7953176 0.8582054 0.9187921
#> 1940 0.5405571 0.5374791 0.5291019 0.9033382 0.7091118 0.8762565 0.8953569
#> 1941 0.6434314 0.6368938 0.6907372 0.7440191 0.7211190 0.7197347 0.8456015
#> 1942 0.4740101 0.6584741 0.5894015 0.7925142 0.7728465 0.8645204 0.7729199
#> 1943 0.3983303 0.5658111 0.5593209 0.7359729 0.8591770 0.9478568 0.4080082
#> 1944 0.5783124 0.8459330 0.5729704 0.9022102 0.7814315 0.7991135 0.8475230
#> 1945 0.6979180 0.5176448 0.6702421 0.6617428 0.8971858 0.8759023 0.8537823
#> 1946 0.5610095 0.5461614 0.6816216 0.7436463 0.7689088 0.8624107 0.7495270
#> 1947 0.5379757 0.6797362 0.5702556 0.7223069 0.7964753 0.9079677 0.8950648
#> 1956 0.3816625 0.9185458 0.5682286 0.8004999 0.8592785 0.7956259 0.7859797
#> 1958 0.4996854 0.7136264 0.6245436 0.7758835 0.8015440 0.8803439 0.7930951
#> 1963 0.7343709 0.7765344 0.4813338 0.7351980 0.9103578 0.9148416 0.8438249
#> 1982 0.3530917 0.5776270 0.4282049 0.8557601 0.7327097 0.5362182 0.7591880
#> 1987 0.7182321 0.6710916 0.6630386 0.9171784 0.6622344 0.7625898 0.7001842
#> 1996 0.6699620 0.8440536 0.8166522 0.7837611 0.8191477 0.7862086 0.7723192
#> 1998 0.3579328 0.7181693 0.7684552 0.7658872 0.7051487 0.5130837 0.8288517
#> 2001 0.5634970 0.6932667 0.8020038 0.6028661 0.6353235 0.6704315 0.8589832
#> 2002 0.5617098 0.5448446 0.6370582 0.4335519 0.4388299 0.6226120 0.7209833
#> 2003 0.7577440 0.8093993 0.7880737 0.7878107 0.6579302 0.7851849 0.8007699
#> 2004 0.7310913 0.6711173 0.7002390 0.6407120 0.5288406 0.6833411 0.8008550
#> 2005 0.7910839 0.6910834 0.8752354 0.6653140 0.5674695 0.6607453 0.7564603
#> 2006 0.7309871 0.6166171 0.7297183 0.9040646 0.7267427 0.7200987 0.8526122
#> 2007 0.8229079 0.6203694 0.6063674 0.6926046 0.6292379 0.7270578 0.9040652
#> 2008 0.8994217 0.7257280 0.7842818 0.6377163 0.6405207 0.7671999 0.8106575
#> 2009 0.6826191 0.7008902 0.7045566 0.6717985 0.5755364 0.6401288 0.7744343
#> 2010 0.6289706 0.6511699 0.6319350 0.8697677 0.6485905 0.7381761 0.3854359
#> 2011 0.6776835 0.5889900 0.6524823 0.6042298 0.6340002 0.6732079 0.8386350
#> 2012 0.8994721 0.7040144 0.8377249 0.8563200 0.6716421 0.7559523 0.8626347
#> 2013 0.7752997 0.6677967 0.8101452 0.6744288 0.6603008 0.6983289 0.7310586
#> 2014 0.7339762 0.6758586 0.7156221 0.7147587 0.5725543 0.7397914 0.8789146
#> 2015 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000
#> 2023 0.6571767 0.5089568 0.7012753 0.7724170 0.6449347 0.6535390 0.8454285
#> 2025 0.6961184 0.6345543 0.6622214 0.7090815 0.6813155 0.7266704 0.7920297
#> 2030 0.7604320 0.6153391 0.5633833 0.8663615 0.6764906 0.7330092 0.7777399
#> 2049 0.6649705 0.6512476 0.6286337 0.5437480 0.5919571 0.5643835 0.7885002
#> 2054 0.8612913 0.7422022 0.8938621 0.6620973 0.4396344 0.5531337 0.6520387
#> 2063 0.6598454 0.4774597 0.6813138 0.8004001 0.7737287 0.6917946 0.8455467
#> 2065 0.5534703 0.6510243 0.7006144 0.5161663 0.6417995 0.4933453 0.8153820
#> 2509 0.7490855 0.9048391 0.7704414 0.9320390 0.7864180 0.7082876 0.9100650
#> 2510 0.6668542 0.7696947 0.6682990 0.7250665 0.6835603 0.7147306 0.4750296
#> 2511 0.7579439 0.7868144 0.6956927 0.7894927 0.6854352 0.7602367 0.8006712
#> 2512 0.9144185 0.7698143 0.8220121 0.7749258 0.7593515 0.7076195 0.8725702
#> 2513 0.8477743 0.7996865 0.8910093 0.9596027 0.8138266 0.7862683 0.8998671
#> 2514 0.8031485 0.8586382 0.7543570 0.9207710 0.8244946 0.7867896 0.9154337
#> 2515 0.8994217 0.7257280 0.7842818 0.6377163 0.6405207 0.7671999 0.8106575
#> 2516 0.7976644 0.7794093 0.7552953 0.6800411 0.6557934 0.7865668 0.8254725
#> 2517 0.7998028 0.9016114 0.7927039 0.7880021 0.8139423 0.7402485 0.8366852
#> 2518 0.6619748 0.7847207 0.7978767 0.7579600 0.7358209 0.8124995 0.8535294
#> 2519 0.8106886 0.9146281 0.7647812 0.9588351 0.8422925 0.7632575 0.8848671
#> 2520 0.6204750 0.8905856 0.8454009 0.8718080 0.7490167 0.7732024 0.9029751
#> 2523 0.6825285 0.7004225 0.7012081 0.6831498 0.6637352 0.6979970 0.7646989
#> 2525 0.7601357 0.8184057 0.7324799 0.9009854 0.7479087 0.7790977 0.9030781
#> 2529 0.8390816 0.7484916 0.6641822 0.8073170 0.6229594 0.7738022 0.8373360
#> 2530 0.8193722 0.7629272 0.6433692 0.7121566 0.7166667 0.7075828 0.7427822
#> 2549 0.7033649 0.8180579 0.6538924 0.7941880 0.8748944 0.7394230 0.8710612
#> 2554 0.8521677 0.8628629 0.7787041 0.6946087 0.5017405 0.4827680 0.5875430
#> 2563 0.7434808 0.6507240 0.7215019 0.6705795 0.6565985 0.7469176 0.7451171
#> 2565 0.6112267 0.8736828 0.8568495 0.8110309 0.7276802 0.6896818 0.9189238
#> 2568 0.9137641 0.8294239 0.8691601 0.7806549 0.8287695 0.8916775 0.4597642
#> 2569 0.8707308 0.8106133 0.9144315 0.8128877 0.8632691 0.7769313 0.7355522
#> 2570 0.7040182 0.8192466 0.8367052 0.8061557 0.8592095 0.8643940 0.8916319
#> 2571 0.8980644 0.8538344 0.8477900 0.9484161 0.8854610 0.9192818 0.8908353
#> 2572 0.9310776 0.9452853 0.9655906 0.9258442 0.8989086 0.8983337 0.8662678
#> 2573 0.6826191 0.7008902 0.7045566 0.6717985 0.5755364 0.6401288 0.7744343
#> 2574 0.8548945 0.8538971 0.8694157 0.7320261 0.7791078 0.8181005 0.7568119
#> 2575 0.9073102 0.8627472 0.9023486 0.8074219 0.8532146 0.8433871 0.8553694
#> 2576 0.7944907 0.8135220 0.7700421 0.7296027 0.7743164 0.7863107 0.7791778
#> 2577 0.9372325 0.9436876 0.9624611 0.9510594 0.8752891 0.9360711 0.9170599
#> 2578 0.8569288 0.9812481 0.8269443 0.8926661 0.9191955 0.8957204 0.8990204
#> 2581 0.8686766 0.7268353 0.9218051 0.7505882 0.7376643 0.7490540 0.8101974
#> 2583 0.9597278 0.8985922 0.9278826 0.9627170 0.8841615 0.8529399 0.9431549
#> 2584 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000
#> 2587 0.8464513 0.8035125 0.8586486 0.8682101 0.7816271 0.8316865 0.7741434
#> 2588 0.7361554 0.8345240 0.7929781 0.7711407 0.8108712 0.8375419 0.6754297
#> 2607 0.7976519 0.8752700 0.8234962 0.8159081 0.7969103 0.5611656 0.8960163
#> 2612 0.6686772 0.8539835 0.6529513 0.7565871 0.6419350 0.7699715 0.5589230
#> 2621 0.7794272 0.6792549 0.7516028 0.7354484 0.7274394 0.7210184 0.7985833
#> 2623 0.8564784 0.9256626 0.7898191 0.8094696 0.8319388 0.5666374 0.8594475
#> 3376 0.9597278 0.8985922 0.9278826 0.9627170 0.8841615 0.8529399 0.9431549
#> 3377 0.9554305 0.9443506 0.9036043 0.9282397 0.8180109 0.9123169 0.8874272
#> 3378 0.6961184 0.6345543 0.6622214 0.7090815 0.6813155 0.7266704 0.7920297
#> 3379 0.8517078 0.8125977 0.8746544 0.8725452 0.8306379 0.9633677 0.7875392
#> 3380 0.7528950 0.9243339 0.7971816 0.8044205 0.7749197 0.9136455 0.7044920
#> 3381 0.8122490 0.8635068 0.8089145 0.7000906 0.7187461 0.8553562 0.7621894
#> 3382 0.8224957 0.9125546 0.8132751 0.8702896 0.9540080 0.9145321 0.9043968
#> 3384 0.8818898 0.9501689 0.8949569 0.7665864 0.8776614 0.9416215 0.7664634
#> 3385 0.8924499 0.7831593 0.8535575 0.8265862 0.8383720 0.8265907 0.9078400
#> 3386 0.9488774 0.8804913 0.9005921 0.9196219 0.7926229 0.8584566 0.8623250
#> 3387 0.8963388 0.8305743 0.8990000 0.8152151 0.8080619 0.9086057 0.5037498
#> 3389 0.7236259 0.7862493 0.8070550 0.8434387 0.8522650 0.8303033 0.9227739
#> 3390 0.9075046 0.8239667 0.8102703 0.9268093 0.9246501 0.8627396 0.9080293
#> 3399 0.7668021 0.8608481 0.7707404 0.7995640 0.7356989 0.6503352 0.8479968
#> 3404 0.6943736 0.8051900 0.6250551 0.7712563 0.5717104 0.6761627 0.6058501
#> 3413 0.8101221 0.7560888 0.7848747 0.7633097 0.8223585 0.8541457 0.8059319
#> 3415 0.8427955 0.9376568 0.8098916 0.7866375 0.8875763 0.6174783 0.8453166
#> 4108 0.7114734 0.7928909 0.6116567 0.8038941 0.7454125 0.7359052 0.7991260
#> 4109 0.8319700 0.8768958 0.7094888 0.9191518 0.7465004 0.6490593 0.9129162
#> 4110 0.6381953 0.8963398 0.7253519 0.6787163 0.7402729 0.5387100 0.7947758
#> 4111 0.7976519 0.8752700 0.8234962 0.8159081 0.7969103 0.5611656 0.8960163
#> 4112 0.5782227 0.7337154 0.5333477 0.7741512 0.5886008 0.3726808 0.4889540
#> 4113 0.7931904 0.7754686 0.7989653 0.6510284 0.8038818 0.5547366 0.7577538
#> 4114 0.7566309 0.8980779 0.7894750 0.8415068 0.6178041 0.6447505 0.8175159
#> 4115 0.7122020 0.8161078 0.7029167 0.5986094 0.6407715 0.6716358 0.7585783
#> 4116 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000
#> 4117 0.7842405 0.8256992 0.8575105 0.8261453 0.8703876 0.5816147 0.9527392
#> 4121 0.6531111 0.6419043 0.5788743 0.6598171 0.6281053 0.7220298 0.8036372
#> 4123 0.7911258 0.8497008 0.6443039 0.9087682 0.7255157 0.8499663 0.8887808
#> 4125 0.7829215 0.9076337 0.7832022 0.6472381 0.6680316 0.5703209 0.4218827
#> 4188 0.7216594 0.8841878 0.7310757 0.6011360 0.6592371 0.6977111 0.6790087
#> 4189 0.7686302 0.6982829 0.5631986 0.8839926 0.5790493 0.6808308 0.5998148
#> 4190 0.7795261 0.7932280 0.6994745 0.7056047 0.5559341 0.6596967 0.6404416
#> 4191 0.5782227 0.7337154 0.5333477 0.7741512 0.5886008 0.3726808 0.4889540
#> 4192 0.7270693 0.8812200 0.6281664 0.7263252 0.6512205 0.7179527 0.4917388
#> 4193 0.6158164 0.7056519 0.6393800 0.5825052 0.5192118 0.5795986 0.5150619
#> 4195 0.5364543 0.8543410 0.7798650 0.7753778 0.5908455 0.6844365 0.5389026
#> 4196 0.7247930 0.6642733 0.6781498 0.8485618 0.5723669 0.6039984 0.5518993
#> 4198 0.5413853 0.8364384 0.7140010 0.6896632 0.4968530 0.3790119 0.5402748
#> 4199 0.6686772 0.8539835 0.6529513 0.7565871 0.6419350 0.7699715 0.5589230
#> 4200 0.6069394 0.7415713 0.5954225 0.7517913 0.7400904 0.7615621 0.5593744
#> 4269 0.8996051 0.8036907 0.8711026 0.8508671 0.9195261 0.9002020 0.7403269
#> 4270 0.6848842 0.7418962 0.8553528 0.6084232 0.7956712 0.6599917 0.7669705
#> 4271 0.7794272 0.6792549 0.7516028 0.7354484 0.7274394 0.7210184 0.7985833
#> 4272 0.7102381 0.6167201 0.7214813 0.8843844 0.7902330 0.8108347 0.3690114
#> 4276 0.8564784 0.9256626 0.7898191 0.8094696 0.8319388 0.5666374 0.8594475
#> 4277 0.9186954 0.8022444 0.7164092 0.6092826 0.7004986 0.5485188 0.4340778
#> tmin_wt prec_sm prec_wt
#> 1 0.8176944 0.8985942 0.7581239
#> 2 0.8020310 0.7862903 0.7880893
#> 3 0.8081509 0.9144520 0.8561890
#> 4 0.7507878 0.8485233 0.7520979
#> 5 0.8201164 0.8669256 0.8044956
#> 6 0.6128309 0.5732956 0.5873260
#> 7 0.7704671 0.8462441 0.8518476
#> 8 0.8857062 0.8230202 0.9381409
#> 9 0.8252185 0.9071896 0.8473933
#> 10 0.7396663 0.5620386 0.8289416
#> 11 0.7009302 0.8595710 0.7909524
#> 12 0.6096978 0.7682660 0.6518564
#> 13 0.9033549 0.9409273 0.8565219
#> 18 1.0000000 1.0000000 1.0000000
#> 19 0.8247280 0.9412633 0.8858784
#> 21 0.9068691 0.8845322 0.9330794
#> 24 0.7382303 0.8470935 0.6658473
#> 25 0.8224112 0.8800080 0.8056829
#> 33 0.8717768 0.9121039 0.9248377
#> 34 0.8676489 0.8124275 0.7218167
#> 50 0.8005374 0.8535124 0.8784292
#> 74 0.7613116 0.8253154 0.6390805
#> 79 0.5557265 0.8784552 0.5868745
#> 88 0.6855011 0.7166183 0.5547523
#> 90 0.8123958 0.9155381 0.8656301
#> 93 0.8932909 0.8558383 0.7151951
#> 94 0.6480385 0.9255650 0.7516851
#> 95 0.8969107 0.9044971 0.6994340
#> 96 0.7754047 0.9218474 0.7236699
#> 97 0.6532217 0.5251019 0.5706751
#> 98 0.8455637 0.9076088 0.7398504
#> 99 0.7638218 0.7617306 0.8139587
#> 100 0.8642642 0.9417216 0.7514253
#> 101 0.6381588 0.4740951 0.6027616
#> 102 0.7767636 0.9076636 0.7341187
#> 103 0.7168274 0.8395150 0.6655752
#> 104 0.8164410 0.8848404 0.8019385
#> 106 1.0000000 1.0000000 1.0000000
#> 109 0.8176944 0.8985942 0.7581239
#> 110 0.7847311 0.8773507 0.7252305
#> 112 0.7737257 0.8007560 0.7698545
#> 115 0.8841109 0.8997529 0.7192031
#> 116 0.7955509 0.9153769 0.7133313
#> 124 0.8878241 0.8847317 0.8244580
#> 125 0.7520223 0.7461242 0.8189544
#> 141 0.8636273 0.7774829 0.7799674
#> 165 0.7259385 0.8151307 0.7192481
#> 170 0.6581079 0.8204418 0.6391338
#> 179 0.7059809 0.6381537 0.6151683
#> 181 0.8780714 0.8482454 0.8748850
#> 184 0.7098915 0.8319747 0.8394319
#> 185 0.9061853 0.9047151 0.9428064
#> 186 0.8602294 0.8893744 0.9448031
#> 187 0.6592058 0.4397644 0.5172076
#> 188 0.8557104 0.8119116 0.8870082
#> 189 0.7621820 0.6524653 0.7922272
#> 190 0.8822448 0.8482765 0.9307007
#> 191 0.7119483 0.4479306 0.8324586
#> 192 0.7797113 0.8038113 0.9389183
#> 193 0.7054885 0.9704159 0.8090570
#> 194 0.8218604 0.7655502 0.9007999
#> 196 0.8932909 0.8558383 0.7151951
#> 198 1.0000000 1.0000000 1.0000000
#> 199 0.8020310 0.7862903 0.7880893
#> 200 0.8170397 0.7510147 0.7945163
#> 202 0.7889547 0.7062882 0.7940067
#> 205 0.8753227 0.9219951 0.6775653
#> 206 0.8742457 0.8494289 0.8892294
#> 214 0.9019870 0.7484992 0.8189078
#> 215 0.7606861 0.6428546 0.6319289
#> 231 0.9232631 0.7065216 0.8951832
#> 255 0.6993491 0.7536174 0.5147757
#> 260 0.6536177 0.7191558 0.6058045
#> 269 0.7581057 0.5873621 0.5779829
#> 271 0.8668034 0.7340229 0.7630915
#> 274 0.6443758 0.8950372 0.8046132
#> 275 0.8278522 0.9040948 0.8638236
#> 276 0.4730409 0.5333798 0.5979475
#> 277 0.6302501 0.8788167 0.9396043
#> 278 0.7517248 0.7690495 0.8687151
#> 279 0.6733839 0.9439359 0.8513024
#> 280 0.8447579 0.5441946 0.7882963
#> 281 0.5599295 0.8878519 0.8622329
#> 282 0.4540040 0.8123691 0.6814149
#> 283 0.7382266 0.8993220 0.8375959
#> 284 1.0000000 1.0000000 1.0000000
#> 285 0.6480385 0.9255650 0.7516851
#> 287 0.7098915 0.8319747 0.8394319
#> 288 0.8081509 0.9144520 0.8561890
#> 289 0.6970324 0.9056440 0.8962259
#> 291 0.7802963 0.8422037 0.8824308
#> 294 0.6300823 0.9026465 0.7963348
#> 295 0.7743708 0.9211447 0.9186881
#> 303 0.7000592 0.8625106 0.8672297
#> 304 0.7367940 0.7592034 0.7035514
#> 320 0.7213956 0.8368434 0.8890678
#> 344 0.7911009 0.8206265 0.5137552
#> 349 0.4062915 0.8509779 0.7152637
#> 358 0.6860897 0.7096755 0.6859566
#> 360 0.6416288 0.8598521 0.8242430
#> 363 0.7715302 0.9777720 0.9221621
#> 364 0.7073789 0.4651551 0.4911180
#> 365 0.8706746 0.9000604 0.8485327
#> 366 0.7135649 0.6863593 0.7547841
#> 367 0.8551345 0.9264237 0.9001293
#> 368 0.6252877 0.4658948 0.7858926
#> 369 0.8186853 0.8919474 0.9278040
#> 370 0.7649416 0.8782030 0.8409974
#> 371 0.7706237 0.8210518 0.8848708
#> 372 0.6443758 0.8950372 0.8046132
#> 373 0.8969107 0.9044971 0.6994340
#> 375 0.9061853 0.9047151 0.9428064
#> 376 0.7507878 0.8485233 0.7520979
#> 377 0.7804886 0.8232170 0.7555339
#> 378 1.0000000 1.0000000 1.0000000
#> 379 0.7353854 0.7468360 0.7548263
#> 382 0.9634170 0.9617562 0.6469229
#> 383 0.8157288 0.9429046 0.8374351
#> 391 0.8549338 0.8048892 0.7811998
#> 392 0.7133767 0.6750720 0.6069906
#> 408 0.8762595 0.7502141 0.8560934
#> 432 0.6533657 0.7870134 0.5019231
#> 437 0.7165014 0.7786559 0.5652815
#> 446 0.6917895 0.6191175 0.5378770
#> 448 0.8526891 0.7775040 0.7304528
#> 451 0.5649437 0.4795817 0.5363409
#> 452 0.7439384 0.9174775 0.9147337
#> 453 0.7674936 0.7057818 0.8042065
#> 454 0.7868738 0.9444081 0.9516702
#> 455 0.8453477 0.4591206 0.8124028
#> 456 0.6701846 0.9113598 0.9794709
#> 457 0.5692551 0.8625817 0.7721139
#> 458 0.8069124 0.8407338 0.9122603
#> 459 0.8278522 0.9040948 0.8638236
#> 460 0.7754047 0.9218474 0.7236699
#> 462 0.8602294 0.8893744 0.9448031
#> 463 0.8201164 0.8669256 0.8044956
#> 464 0.7570784 0.8420699 0.8183878
#> 465 0.7715302 0.9777720 0.9221621
#> 466 0.8098510 0.7628359 0.8108577
#> 469 0.7460751 0.9531871 0.6813420
#> 470 0.8647987 0.9586066 0.8954153
#> 478 0.8194726 0.8248833 0.8291436
#> 479 0.7516254 0.6938965 0.6395266
#> 481 1.0000000 1.0000000 1.0000000
#> 495 0.8391543 0.7484254 0.9117936
#> 519 0.7512594 0.7818190 0.5079493
#> 524 0.5217831 0.7933974 0.6001177
#> 533 0.8197378 0.6153086 0.5722961
#> 535 0.7580498 0.7962699 0.7700624
#> 538 0.8009693 0.5101096 0.5766338
#> 539 0.6623881 0.6786564 0.6184091
#> 540 0.7549487 0.5053834 0.5448371
#> 541 0.4391393 0.4970182 0.5238599
#> 542 0.8731552 0.5096231 0.5288525
#> 543 0.8338300 0.4341234 0.4208891
#> 544 0.6894417 0.5732255 0.5419813
#> 545 0.4730409 0.5333798 0.5979475
#> 546 0.6532217 0.5251019 0.5706751
#> 548 0.6592058 0.4397644 0.5172076
#> 549 0.6128309 0.5732956 0.5873260
#> 550 0.7635128 0.5761570 0.6487284
#> 551 0.7073789 0.4651551 0.4911180
#> 552 0.6546089 0.6270160 0.6225006
#> 553 1.0000000 1.0000000 1.0000000
#> 555 0.7263292 0.4732403 0.6945617
#> 556 0.6701915 0.4900354 0.5330505
#> 564 0.7063407 0.5962551 0.5852828
#> 565 0.6779058 0.6960102 0.7215075
#> 567 0.5649437 0.4795817 0.5363409
#> 581 0.6822944 0.5830444 0.5834862
#> 605 0.4161127 0.5361018 0.6456181
#> 610 0.8496869 0.6281257 0.7397787
#> 619 0.4270444 0.5233444 0.6833346
#> 621 0.7555767 0.6186647 0.6300244
#> 624 0.7812128 0.7149983 0.8536550
#> 625 0.9269231 0.9188476 0.9017867
#> 626 0.5924492 0.4250099 0.8301348
#> 627 0.9211590 0.9732996 0.9027073
#> 628 0.8052720 0.7855081 0.7104143
#> 629 0.8371475 0.8457964 0.8749595
#> 630 0.6302501 0.8788167 0.9396043
#> 631 0.8455637 0.9076088 0.7398504
#> 633 0.8557104 0.8119116 0.8870082
#> 634 0.7704671 0.8462441 0.8518476
#> 635 0.8837220 0.8607871 0.8803004
#> 636 0.8706746 0.9000604 0.8485327
#> 637 0.7986074 0.7552299 0.8667776
#> 638 0.8009693 0.5101096 0.5766338
#> 640 0.8631334 0.8723786 0.7377459
#> 641 0.8227271 0.9356829 0.9450649
#> 649 0.8980183 0.8671065 0.8746578
#> 650 0.7859041 0.6972528 0.6757591
#> 652 0.7439384 0.9174775 0.9147337
#> 653 1.0000000 1.0000000 1.0000000
#> 666 0.8805160 0.7248703 0.9271862
#> 690 0.5893018 0.7637164 0.5116059
#> 695 0.7706994 0.8156101 0.6586164
#> 704 0.6184221 0.5900085 0.6273677
#> 706 0.9364353 0.7980153 0.8116049
#> 709 0.8299276 0.7498709 0.8475586
#> 710 0.6520435 0.6205501 0.7718364
#> 711 0.7480285 0.7268078 0.7936060
#> 712 0.6442850 0.6433510 0.6645899
#> 713 0.9289181 0.8493165 0.8681874
#> 714 0.7517248 0.7690495 0.8687151
#> 715 0.7638218 0.7617306 0.8139587
#> 717 0.7621820 0.6524653 0.7922272
#> 718 0.8857062 0.8230202 0.9381409
#> 719 0.8746788 0.8281545 0.9095914
#> 720 0.7135649 0.6863593 0.7547841
#> 721 0.9393732 0.8914435 0.9530268
#> 722 0.6623881 0.6786564 0.6184091
#> 724 0.6943823 0.6948029 0.7260104
#> 725 0.8013361 0.7157050 0.8088269
#> 733 0.8374484 0.8260238 0.9650206
#> 734 0.9728289 0.9641569 0.7798486
#> 736 0.7674936 0.7057818 0.8042065
#> 737 0.7812128 0.7149983 0.8536550
#> 738 1.0000000 1.0000000 1.0000000
#> 750 0.7707129 0.8586376 0.8911353
#> 774 0.6860058 0.7497967 0.6358829
#> 779 0.5941898 0.8205893 0.6468809
#> 788 0.6109830 0.7491270 0.6149634
#> 790 0.8301004 0.9057824 0.9203771
#> 793 0.6341499 0.4921841 0.8182059
#> 794 0.8684452 0.9334160 0.9407854
#> 795 0.7483674 0.8261382 0.7709642
#> 796 0.8851676 0.8917849 0.9444831
#> 797 0.6733839 0.9439359 0.8513024
#> 798 0.8642642 0.9417216 0.7514253
#> 800 0.8822448 0.8482765 0.9307007
#> 801 0.8252185 0.9071896 0.8473933
#> 802 0.9141447 0.8922343 0.8408557
#> 803 0.8551345 0.9264237 0.9001293
#> 804 0.8451628 0.8116152 0.8518584
#> 805 0.7549487 0.5053834 0.5448371
#> 806 1.0000000 1.0000000 1.0000000
#> 807 0.8356748 0.9188396 0.6694830
#> 808 0.8652652 0.9612592 0.8773482
#> 816 0.9377104 0.8687878 0.8734280
#> 817 0.8351336 0.7356056 0.6743755
#> 819 0.7868738 0.9444081 0.9516702
#> 820 0.9269231 0.9188476 0.9017867
#> 821 0.8299276 0.7498709 0.8475586
#> 833 0.9090370 0.7942087 0.9488409
#> 857 0.6365933 0.8097564 0.5525393
#> 862 0.7055895 0.8249297 0.5882587
#> 871 0.6440935 0.6540427 0.5601675
#> 873 0.9454003 0.8429532 0.8124112
#> 876 0.5172505 0.4352762 0.7990390
#> 877 0.4202025 0.4499956 0.6726066
#> 878 0.6902913 0.5365116 0.7782716
#> 879 0.8447579 0.5441946 0.7882963
#> 880 0.6381588 0.4740951 0.6027616
#> 882 0.7119483 0.4479306 0.8324586
#> 883 0.7396663 0.5620386 0.8289416
#> 884 0.6316571 0.5317715 0.8280459
#> 885 0.6252877 0.4658948 0.7858926
#> 886 0.6973302 0.6192544 0.8068792
#> 887 0.4391393 0.4970182 0.5238599
#> 888 0.6341499 0.4921841 0.8182059
#> 889 0.6067554 0.4930945 0.6274438
#> 890 0.7595298 0.4784564 0.8413232
#> 898 0.6656141 0.4804350 0.7698262
#> 899 0.6344088 0.6490429 0.5763963
#> 901 0.8453477 0.4591206 0.8124028
#> 902 0.5924492 0.4250099 0.8301348
#> 903 0.6520435 0.6205501 0.7718364
#> 913 1.0000000 1.0000000 1.0000000
#> 915 0.6845019 0.6759214 0.8069467
#> 939 0.7371509 0.5566190 0.5676723
#> 944 0.3796264 0.5943687 0.5720360
#> 953 0.8203005 0.8169961 0.5373994
#> 955 0.6045868 0.5746877 0.7178913
#> 958 0.8604804 0.7790916 0.7799011
#> 959 0.7769425 0.8587022 0.9104405
#> 960 0.5599295 0.8878519 0.8622329
#> 961 0.7767636 0.9076636 0.7341187
#> 963 0.7797113 0.8038113 0.9389183
#> 964 0.7009302 0.8595710 0.7909524
#> 965 0.8407216 0.8715477 0.8038024
#> 966 0.8186853 0.8919474 0.9278040
#> 967 0.7413132 0.7668868 0.7981044
#> 968 0.8731552 0.5096231 0.5288525
#> 969 0.8684452 0.9334160 0.9407854
#> 970 0.8274914 0.8701197 0.6867778
#> 971 0.7529936 0.9334908 0.8922524
#> 979 0.8257297 0.8716235 0.8178612
#> 980 0.7627283 0.7093716 0.6412387
#> 982 0.6701846 0.9113598 0.9794709
#> 983 0.9211590 0.9732996 0.9027073
#> 984 0.7480285 0.7268078 0.7936060
#> 994 0.5172505 0.4352762 0.7990390
#> 996 0.8061388 0.7365726 0.9016739
#> 1020 0.5169788 0.7643151 0.5046003
#> 1025 0.8308183 0.8252749 0.6055535
#> 1034 0.5406012 0.5990058 0.5777319
#> 1036 0.8808695 0.8098248 0.7648074
#> 1039 0.6710494 0.7509316 0.7759436
#> 1040 0.4540040 0.8123691 0.6814149
#> 1041 0.7168274 0.8395150 0.6655752
#> 1043 0.7054885 0.9704159 0.8090570
#> 1044 0.6096978 0.7682660 0.6518564
#> 1045 0.7133150 0.7324304 0.6428130
#> 1046 0.7649416 0.8782030 0.8409974
#> 1047 0.6337746 0.6942316 0.6524216
#> 1048 0.8338300 0.4341234 0.4208891
#> 1049 0.7483674 0.8261382 0.7709642
#> 1050 0.7830720 0.8989990 0.5679250
#> 1051 0.6406022 0.8241860 0.7147975
#> 1059 0.7293727 0.7320204 0.6863930
#> 1060 0.6548546 0.6342214 0.5607770
#> 1062 0.5692551 0.8625817 0.7721139
#> 1063 0.8052720 0.7855081 0.7104143
#> 1064 0.6442850 0.6433510 0.6645899
#> 1074 0.4202025 0.4499956 0.6726066
#> 1076 0.7139050 0.6969082 0.7378041
#> 1081 1.0000000 1.0000000 1.0000000
#> 1100 0.4460835 0.7496316 0.5024135
#> 1105 0.9386373 0.7012208 0.4993788
#> 1114 0.4654127 0.5866245 0.4746589
#> 1116 0.7731742 0.7223938 0.6638238
#> 1119 0.7382266 0.8993220 0.8375959
#> 1120 0.8164410 0.8848404 0.8019385
#> 1121 1.0000000 1.0000000 1.0000000
#> 1122 0.8218604 0.7655502 0.9007999
#> 1123 0.9033549 0.9409273 0.8565219
#> 1124 0.9031493 0.9612463 0.8203026
#> 1125 0.7706237 0.8210518 0.8848708
#> 1126 0.9453861 0.8952268 0.8642482
#> 1127 0.6894417 0.5732255 0.5419813
#> 1128 0.8851676 0.8917849 0.9444831
#> 1129 0.7511480 0.8222975 0.6725546
#> 1130 0.8681874 0.8560350 0.8416715
#> 1138 0.9047307 0.9277597 0.8939025
#> 1139 0.9253840 0.8289363 0.7178164
#> 1141 0.8069124 0.8407338 0.9122603
#> 1142 0.8371475 0.8457964 0.8749595
#> 1143 0.9289181 0.8493165 0.8681874
#> 1153 0.6902913 0.5365116 0.7782716
#> 1155 0.8375038 0.8595663 0.9391187
#> 1160 0.6710494 0.7509316 0.7759436
#> 1179 0.6973781 0.8469757 0.5926163
#> 1184 0.6219477 0.8416466 0.5913303
#> 1193 0.6474228 0.7125010 0.5635088
#> 1195 0.8883728 0.9404872 0.8450155
#> 1578 0.7804886 0.8232170 0.7555339
#> 1579 0.8844691 0.8831898 0.9456927
#> 1580 0.7635128 0.5761570 0.6487284
#> 1581 0.9141447 0.8922343 0.8408557
#> 1582 0.7637531 0.8178503 0.7489206
#> 1583 0.8624601 0.8673329 0.8315105
#> 1585 0.7847311 0.8773507 0.7252305
#> 1586 1.0000000 1.0000000 1.0000000
#> 1587 0.8247280 0.9412633 0.8858784
#> 1588 0.6970324 0.9056440 0.8962259
#> 1589 0.8170397 0.7510147 0.7945163
#> 1591 0.8800808 0.9324170 0.8894360
#> 1592 0.8837627 0.8080527 0.7157394
#> 1594 0.7570784 0.8420699 0.8183878
#> 1595 0.8837220 0.8607871 0.8803004
#> 1596 0.8746788 0.8281545 0.9095914
#> 1606 0.6316571 0.5317715 0.8280459
#> 1608 0.8633190 0.8444101 0.8791894
#> 1613 0.7133150 0.7324304 0.6428130
#> 1632 0.6016739 0.8403413 0.5735983
#> 1637 0.6739489 0.8732335 0.6741468
#> 1646 0.6045617 0.7079338 0.6380870
#> 1648 0.8972697 0.9164973 0.8428381
#> 1723 0.6546089 0.6270160 0.6225006
#> 1724 0.8451628 0.8116152 0.8518584
#> 1725 0.7186482 0.7580873 0.7182234
#> 1726 0.8390581 0.7808276 0.8192049
#> 1727 1.0000000 1.0000000 1.0000000
#> 1728 0.7737257 0.8007560 0.7698545
#> 1729 0.8844691 0.8831898 0.9456927
#> 1730 0.9068691 0.8845322 0.9330794
#> 1731 0.7802963 0.8422037 0.8824308
#> 1732 0.7889547 0.7062882 0.7940067
#> 1733 0.7353854 0.7468360 0.7548263
#> 1734 0.8698691 0.8541818 0.9332046
#> 1735 0.9286419 0.8920614 0.7395771
#> 1737 0.8098510 0.7628359 0.8108577
#> 1738 0.7986074 0.7552299 0.8667776
#> 1739 0.9393732 0.8914435 0.9530268
#> 1749 0.6973302 0.6192544 0.8068792
#> 1751 0.8063757 0.9020095 0.8941299
#> 1756 0.6337746 0.6942316 0.6524216
#> 1775 0.7039132 0.8127129 0.6049948
#> 1780 0.5846020 0.8630912 0.6411610
#> 1789 0.6456431 0.7884728 0.6071284
#> 1791 0.8491268 0.9366492 0.8824166
#> 1933 0.7988517 0.9214876 0.7395983
#> 1934 0.7186482 0.7580873 0.7182234
#> 1935 0.8841109 0.8997529 0.7192031
#> 1936 0.7637531 0.8178503 0.7489206
#> 1937 0.7382303 0.8470935 0.6658473
#> 1938 0.6300823 0.9026465 0.7963348
#> 1939 0.8753227 0.9219951 0.6775653
#> 1940 0.9634170 0.9617562 0.6469229
#> 1941 0.8349629 0.8001516 0.6992626
#> 1942 0.6942756 0.6854934 0.8047653
#> 1943 0.7263292 0.4732403 0.6945617
#> 1944 0.7460751 0.9531871 0.6813420
#> 1945 0.8631334 0.8723786 0.7377459
#> 1946 0.6943823 0.6948029 0.7260104
#> 1947 0.8356748 0.9188396 0.6694830
#> 1956 0.6067554 0.4930945 0.6274438
#> 1958 0.8561355 0.7675116 0.7094262
#> 1963 0.7830720 0.8989990 0.5679250
#> 1982 0.6314660 0.7950048 0.5484584
#> 1987 0.7383996 0.7776258 0.8785754
#> 1996 0.6758380 0.6422050 0.8889050
#> 1998 0.8329291 0.7841860 0.7599578
#> 2001 0.8390581 0.7808276 0.8192049
#> 2002 0.7955509 0.9153769 0.7133313
#> 2003 0.8624601 0.8673329 0.8315105
#> 2004 0.8224112 0.8800080 0.8056829
#> 2005 0.7743708 0.9211447 0.9186881
#> 2006 0.8742457 0.8494289 0.8892294
#> 2007 0.8157288 0.9429046 0.8374351
#> 2008 0.8784368 0.8362334 0.8251119
#> 2009 0.8026984 0.7032062 0.6418912
#> 2010 0.6701915 0.4900354 0.5330505
#> 2011 0.8647987 0.9586066 0.8954153
#> 2012 0.8227271 0.9356829 0.9450649
#> 2013 0.8013361 0.7157050 0.8088269
#> 2014 0.8652652 0.9612592 0.8773482
#> 2015 1.0000000 1.0000000 1.0000000
#> 2023 0.7595298 0.4784564 0.8413232
#> 2025 0.9077059 0.7612945 0.8924199
#> 2030 0.6406022 0.8241860 0.7147975
#> 2049 0.6811208 0.7807736 0.4754509
#> 2054 0.6060625 0.8224218 0.6869597
#> 2063 0.7280793 0.6373313 0.6566735
#> 2065 0.8327297 0.8090414 0.7710053
#> 2509 0.8376876 0.8012620 0.7616304
#> 2510 0.7063407 0.5962551 0.5852828
#> 2511 0.8194726 0.8248833 0.8291436
#> 2512 0.8980183 0.8671065 0.8746578
#> 2513 0.8374484 0.8260238 0.9650206
#> 2514 0.9377104 0.8687878 0.8734280
#> 2515 0.8784368 0.8362334 0.8251119
#> 2516 0.9019870 0.7484992 0.8189078
#> 2517 0.8800808 0.9324170 0.8894360
#> 2518 0.8878241 0.8847317 0.8244580
#> 2519 0.8717768 0.9121039 0.9248377
#> 2520 0.8698691 0.8541818 0.9332046
#> 2523 0.6656141 0.4804350 0.7698262
#> 2525 0.9121732 0.8031598 0.9112761
#> 2529 0.8549338 0.8048892 0.7811998
#> 2530 0.7293727 0.7320204 0.6863930
#> 2549 0.6868602 0.8363692 0.6236697
#> 2554 0.6787890 0.8428219 0.6201331
#> 2563 0.6781490 0.6557915 0.5888844
#> 2565 0.9384404 0.9014768 0.9079822
#> 2568 0.6779058 0.6960102 0.7215075
#> 2569 0.7516254 0.6938965 0.6395266
#> 2570 0.7859041 0.6972528 0.6757591
#> 2571 0.9728289 0.9641569 0.7798486
#> 2572 0.8351336 0.7356056 0.6743755
#> 2573 0.8026984 0.7032062 0.6418912
#> 2574 0.7606861 0.6428546 0.6319289
#> 2575 0.8837627 0.8080527 0.7157394
#> 2576 0.7520223 0.7461242 0.8189544
#> 2577 0.8676489 0.8124275 0.7218167
#> 2578 0.9286419 0.8920614 0.7395771
#> 2581 0.6344088 0.6490429 0.5763963
#> 2583 0.7733500 0.8517618 0.7140682
#> 2584 1.0000000 1.0000000 1.0000000
#> 2587 0.7133767 0.6750720 0.6069906
#> 2588 0.6548546 0.6342214 0.5607770
#> 2607 0.6599467 0.7314355 0.7390006
#> 2612 0.6061314 0.8243655 0.7450593
#> 2621 0.5961051 0.7575116 0.7317159
#> 2623 0.8335821 0.8865603 0.8444200
#> 3376 0.7733500 0.8517618 0.7140682
#> 3377 0.9090370 0.7942087 0.9488409
#> 3378 0.9077059 0.7612945 0.8924199
#> 3379 0.8762595 0.7502141 0.8560934
#> 3380 0.7139050 0.6969082 0.7378041
#> 3381 0.8636273 0.7774829 0.7799674
#> 3382 0.8063757 0.9020095 0.8941299
#> 3384 0.9232631 0.7065216 0.8951832
#> 3385 0.8633190 0.8444101 0.8791894
#> 3386 0.8005374 0.8535124 0.8784292
#> 3387 0.6822944 0.5830444 0.5834862
#> 3389 0.8805160 0.7248703 0.9271862
#> 3390 0.7707129 0.8586376 0.8911353
#> 3399 0.6785739 0.8239039 0.5756816
#> 3404 0.6723394 0.7991650 0.6282991
#> 3413 0.7278551 0.8520837 0.5990480
#> 3415 0.8950453 0.8895011 0.8555408
#> 4108 0.7259385 0.8151307 0.7192481
#> 4109 0.7039132 0.8127129 0.6049948
#> 4110 0.5893018 0.7637164 0.5116059
#> 4111 0.6599467 0.7314355 0.7390006
#> 4112 0.3878791 0.7361966 0.5345249
#> 4113 0.6016739 0.8403413 0.5735983
#> 4114 0.6533657 0.7870134 0.5019231
#> 4115 0.6993491 0.7536174 0.5147757
#> 4116 1.0000000 1.0000000 1.0000000
#> 4117 0.7613116 0.8253154 0.6390805
#> 4121 0.6772319 0.7316793 0.4909020
#> 4123 0.6297091 0.8332121 0.6835734
#> 4125 0.4161127 0.5361018 0.6456181
#> 4188 0.6739489 0.8732335 0.6741468
#> 4189 0.7165014 0.7786559 0.5652815
#> 4190 0.6536177 0.7191558 0.6058045
#> 4191 0.3878791 0.7361966 0.5345249
#> 4192 0.5557265 0.8784552 0.5868745
#> 4193 0.6581079 0.8204418 0.6391338
#> 4195 0.5846020 0.8630912 0.6411610
#> 4196 0.4226641 0.7204366 0.9168133
#> 4198 0.7289861 0.8574168 0.6824574
#> 4199 0.6061314 0.8243655 0.7450593
#> 4200 0.8496869 0.6281257 0.7397787
#> 4269 0.7581057 0.5873621 0.5779829
#> 4270 0.6322365 0.7477479 0.6488628
#> 4271 0.5961051 0.7575116 0.7317159
#> 4272 0.4270444 0.5233444 0.6833346
#> 4276 0.8335821 0.8865603 0.8444200
#> 4277 0.7555767 0.6186647 0.6300244Shutting down
At the end of the analysis run elements::shutdown to
close the connection to the filehash database.
elements::shutdown()