Challenge and Methodological Approach Summary¶
Environmental pollutants do not respect boundaries between different parts of the environment. However, pollution studies are often limited to a single environmental compartment (for example, air, soil, water, or wildlife). By integrating data across these compartments, we can gain a more complete understanding of how pollutants move through the environment and how ecosystems respond.
In practice, relevant data are often spread across multiple organisations, portals, and formats, making them difficult to discover, access, and combine. The purpose of this notebook, together with the UK Environmental Exposure (UK-EEX) Hub, is to make it easier to find, process, analyse, and visualise environmental data related to chemical pollutants and their impacts.
This notebook demonstrates how data from different environmental compartments can be integrated for the study of a single pollutant. Cadmium (Cd), a heavy metal, is used as an example throughout.
The notebook shows how gridded datasets (such as maps of emissions or soil concentrations) and point-based observations (such as river monitoring sites or wildlife samples) can be combined into a common analytical framework. The resulting datasets can then be used for visualisation, statistical analysis, and machine learning applications. All maps in this notebook are generated using the R package tmap.
Downloading data
The following datasets are used in the is notebook:
Otter data: Biological characteristics, liver metal concentrations, habitat biogeochemistry and habitat contamination sources of UK otters (2006-2017), also available on Datalabs asset repo
Environmental Agency Water Quality Archive: mean Cd data aggregate from the sensor integration tool API mentioned below.
Note that all the datasets needed are provided in the GitHub repo. The EA mean Cd data has been pre-processed by the author.
In addition, the following portals are mentioned:
Metals Pollution¶
Heavy metals are natural constituents of the Earth’s crust. They are stable and cannot be degraded or destroyed, and therefore they tend to accumulate in soils and sediments. However, human activities have drastically altered the biochemical and geochemical cycles and balance of some heavy metals. The principal man-made sources of heavy metals are industrial point sources, e.g. mines, foundries and smelters, and diffuse sources such as combustion by-products, traffic, etc. Relatively volatile heavy metals and those that become attached to air-borne particles (particulates) can be widely dispersed throughout the atmosphere, often being deposited thousands of miles from the site of initial release. In general, the smaller and lighter a particle is, the longer it will stay in the air. Larger particles (greater than 10 micrometers (µm) in diameter) tend to settle to the ground by gravity in a matter of hours whereas the smallest particles (less than 1µm in diameter ) can stay in the atmosphere for weeks and are mostly removed by precipitation.
Causal loop diagram¶
Metals pollution were typically studied in compartments (e.g. air, soil, biota, water). Metals pollution is a complex issue with impacts that span across different environmental compartments and influence ecosystems and human health through the food chain. Systems thinking helps to map these connections and understand that problems like industrial runoff, waste disposal, and agricultural use are not isolated issues but are interconnected parts of a larger system.
By considering the whole system holistically, policymakers and scientists can better identify key leverage points for more effective, integrated strategies that avoid unintended consequences.
To adopt a systems thinking view, a causal loop diagram is often constructed to describe all the potential linkages between environmental pressures and responses. Here is an example:
The difficulty to study across compartments¶
Using cadmium (Cd) as an example chemical, if one would like to visualize Cd pollution across air, land, water, and biota, they will need to go to different portals for each dataset, or downloading the individual datasets.
Air
Soil
Predatory Birds
River water
Here are some example screenshots of web portals:
The following code shows how to plot air and soil pollution maps, individually.
library(tmap)
library(terra)
library(viridis)
library(readr)
library(tidyr)
library(dplyr)
library(sf)
library(cols4all) # for flipping colour bar in tmap
dataset_path <- 'temp/datasets'tmap_mode("plot")
# tm_shape(cd_NAEI_raster ) +
# tm_raster(
# col.scale = tm_scale_continuous_log10(
# ticks = c(5e-5,5e-4, 5e-3,5e-2) # Define log increments for the legend
# )
# )
cd_NAEI_raster <-rast(file.path(dataset_path,'NAEI_maps/naei_cd_2023/GeoTIFF_layers/totalcd23_2023.tif'))
cd_EUSO_raster <-rast(file.path('data/topsoil_Cd_UK_small.tif'))
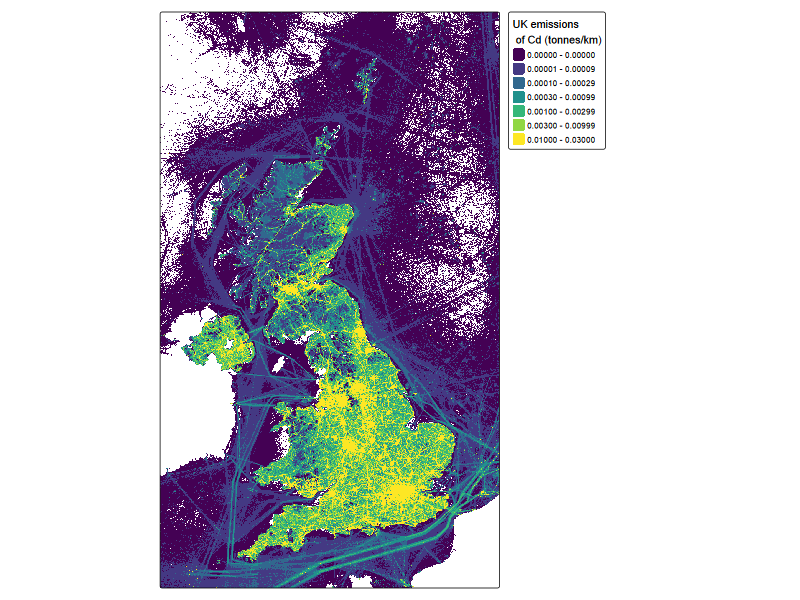
NAEI_tmap <-
tm_shape(cd_NAEI_raster ) +
tm_raster(
col.scale = tm_scale_intervals(
style = 'fixed',
breaks = c(1e-6,1e-5,1e-4,3e-4,1e-3,3e-3,1e-2, 3e-2),
values = "viridis"
#labels = c("low", "medium", "high")
),
col.legend = tm_legend(title = "UK emissions\n of Cd (tonnes/km)",
labels.fomat = 'scientific'),
)
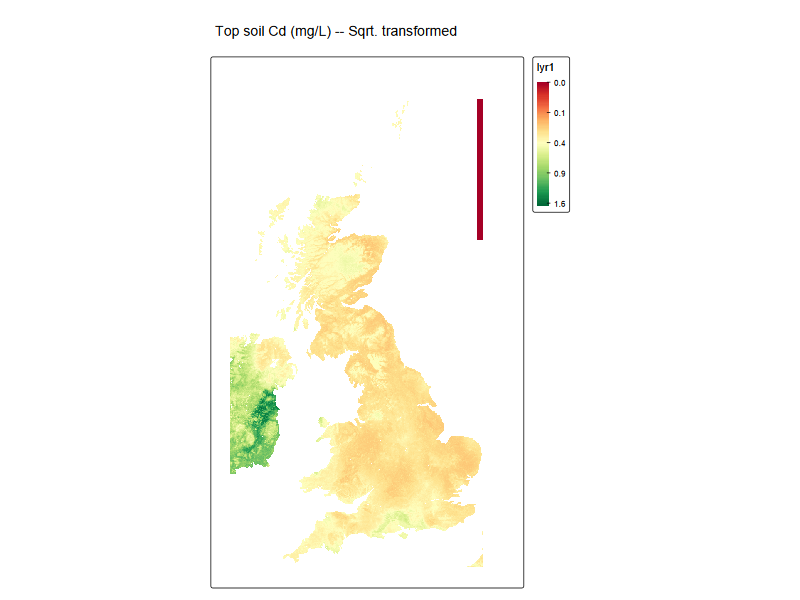
EUSO_tmap <-
tmap::tm_shape(cd_EUSO_raster) +
tmap::tm_raster(
col.scale = tmap::tm_scale_continuous_sqrt(
values = "brewer.rd_yl_gn",
midpoint = NA),
# col.legend = tm_legend(title = "Modelled Cd in soil",
# labels.fomat = 'scientific')
) +
tm_title("Top soil Cd (mg/L) -- Sqrt. transformed")
NAEI_tmap
EUSO_tmap
ℹ tmap modes "plot" - "view"
ℹ toggle with ]8;;x-r-run:tmap::ttm()tmap::ttm()]8;;
This message is displayed once per session.
Warning messages:
1: Values have found that are less than the lowest break. They are assigned to the lowest interval
2: Values have found that are higher than the highest break. They are assigned to the highest interval
#bivariate map
# raster1_projected <- project(cd_EUSO_raster, cd_NAEI_raster , method = "bilinear") # no need if scale matches
raster1_projected <- cd_EUSO_raster
r_stack <- c(raster1_projected , cd_NAEI_raster )
names(r_stack) <- c("var1", "var2")
r_stack$var1[r_stack$var1 == 0] <- 1e-3 # abitrary, just for quantiles
r_stack$var1 = log10(r_stack$var1) # soil
r_stack$var2[r_stack$var2 < 1e-6] <- NA # remove off shore
r_stack$var2 = log10(r_stack$var2) #NAEI
tm_shape(r_stack) +
tm_raster(
col = tm_vars(c("var1", "var2"), multivariate = FALSE),
col.scale = tm_scale_intervals(style = "quantile", n = 3, labels = c("L", "M", "H"),
values = "-carto.earth"))
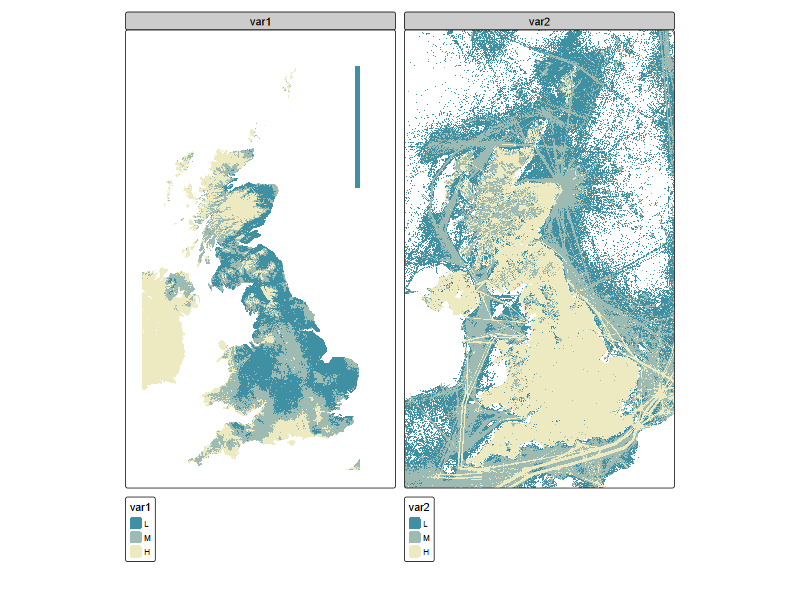
But how are air and soil pollution hotspots co-located? Here we can use an integration tool called bivariate plots. Essentially, this is to colour the pixels on the map with a two-dimensional colour map.
stevens.bluered <- matrix(c("#E8E8E8", "#E4ACAC", "#C85A5A",
"#B0D5DF", "#AD9EA5", "#985356",
"#64ACBE", "#627F8C", "#574249"),
byrow = TRUE, ncol = 3)
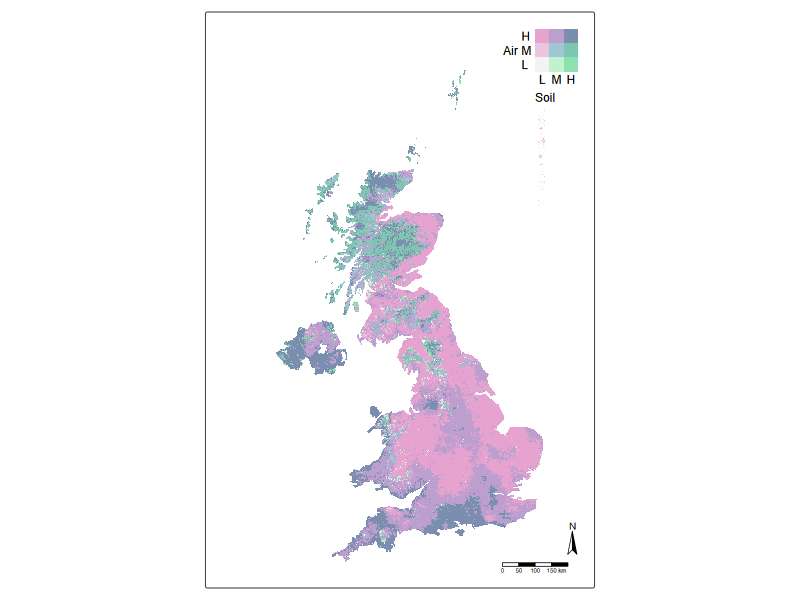
tm_shape(r_stack) +
tm_raster(
col = tm_vars(c("var2", "var1"), multivariate = TRUE),
col.scale = tm_scale_bivariate(
scale1 = tm_scale_intervals(style = "quantile", n = 3, labels = c("L", "M", "H")),
scale2 = tm_scale_intervals(style = "quantile", n = 3, labels = c("L", "M", "H")),
values = "stevens.pinkgreen"), # 97.94% colour-blind friendly
col.legend = tm_legend_bivariate(
position = c("top", "right"),
xlab = "Soil",
ylab = "Air",
xlab.size = 1,
ylab.size = 1,
item.r = 0,
item.width = 1,
item.height = 1,
text.size = 1,
))+
#tm_credits("UKCEH") +
tm_compass(type = "arrow") +
tm_scalebar()+
tm_components(frame = FALSE)+
tm_layout(inner.margins = c(0, 0.15, 0.02, 0.02))
Predatory birds and otters data¶
# otter_metals <- read_csv('/assets/bio-xter-liver-metal-habitat-uk-otters-2006-2017-v1/data/Concentrations_of_inorganic_elements_in_UK_otter_livers_2006–2017.csv')
otter_metals <- read_csv('data/Concentrations_of_inorganic_elements_in_UK_otter_livers_2006–2017.csv')
otter_metals[,c('long','lat')] <-sf_project(from = st_crs(27700), to = st_crs(4326), otter_metals[,c('X','Y')])
tm_shape(st_as_sf(otter_metals, coords = c("long", "lat"), crs = 4326) )+
tm_basemap() +
tm_symbols(
size = "Cd",
fill = "maroon",
col = "black",
lwd = 1,
size.scale = tm_scale(values.scale = 2)
)+
tm_title("Otter Cd (mg/L)")
Rows: 278 Columns: 57
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (6): Sex, AgeClass, Al, Sb, V, Mine
dbl (51): UWCRef, Year, Batch, Weight, Length, sSMI, X, Y, DM, Mn, Fe, Co, N...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
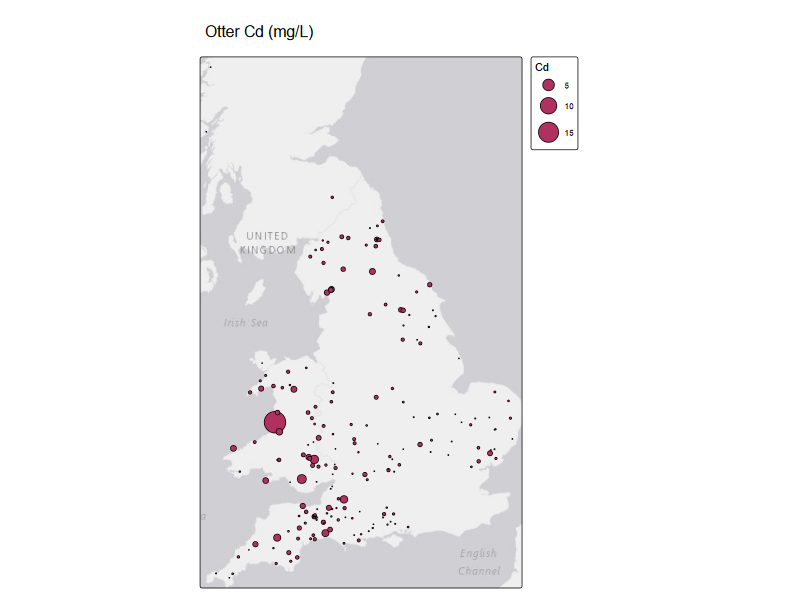
River water quality data¶
riv_metals <- read_csv('data/Cd_mean_2025.csv')
tm_shape(st_as_sf(riv_metals, coords = c("lon", "lat"), crs = 4326) )+
tm_basemap() +
tm_symbols(
size = "Cd_mean",
fill = "steelblue",
# fill.legend = tm_legend(
# title = "Mean Cd (mg/L)",
# show = TRUE
# ),
col = "black",
lwd = 1,
size.scale = tm_scale(values.scale = 2)
) +
tm_title("River mean Cd (mg/L)"
)
New names:
• `` -> `...1`
Rows: 404 Columns: 22
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (10): site_id, site_name, region, G_ID, S_ID, wb_id, organisation, mater...
dbl (12): ...1, easting, northing, min_year, max_year, HA_NUM, rbd_id, mncat...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
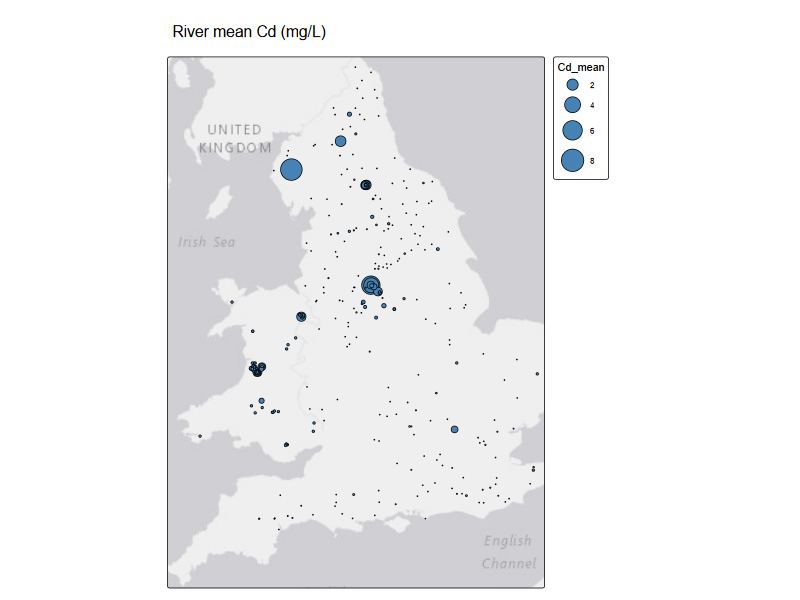
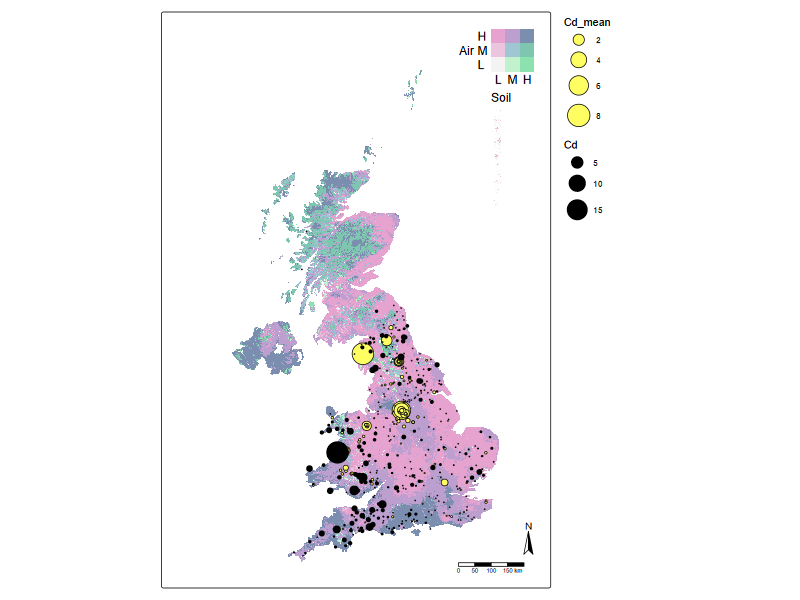
# tmap_mode("view")
# tm_basemap(c(StreetMap = "OpenStreetMap", TopoMap = "OpenTopoMap")) +
# NAEI_tmap
# tmap_mode("view")
tm_shape(r_stack) +
tm_raster(
col = tm_vars(c("var2", "var1"), multivariate = TRUE),
col.scale = tm_scale_bivariate(
scale1 = tm_scale_intervals(style = "quantile", n = 3, labels = c("L", "M", "H")),
scale2 = tm_scale_intervals(style = "quantile", n = 3, labels = c("L", "M", "H")),
values = "stevens.pinkgreen"), # 97.94% colour-blind friendly
col.legend = tm_legend_bivariate(
position = c("top", "right"),
xlab = "Soil",
ylab = "Air",
xlab.size = 1,
ylab.size = 1,
item.r = 0,
item.width = 1,
item.height = 1,
text.size = 1,
))+
tm_shape(st_as_sf(riv_metals, coords = c("lon", "lat"), crs = 4326) )+
tm_symbols(
size = "Cd_mean",
col = "black",
fill = "#FEFE62",
# shape = 1,
lwd = 1,
size.scale = tm_scale(values.scale = 2)
) +
tm_shape(st_as_sf(otter_metals, coords = c("long", "lat"), crs = 4326) )+
tm_symbols(
size = "Cd",
fill = "black", #"#CC79A7",
col = "black",
lwd = 1,
size.scale = tm_scale(values.scale = 2)
)+
#tm_credits("UKCEH") +
tm_compass(type = "arrow") +
tm_scalebar()+
tm_components(frame = FALSE)+
tm_layout(inner.margins = c(0, 0.15, 0.02, 0.02))
Bivariate chloropleth plot for air and soil cadmium levels, overlaid by otter and river water cadmium levels
library(maps)
uk_nuts1 <- terra::vect('data/NUTS_Level_1_January_2018_FCB_in_the_United_Kingdom.shp')
eng_wales <- uk_nuts1[1:10,]
# eng_wales <- terra::aggregate(uk_nuts1[1:10,])
metals_map <- st_as_sf(x = otter_metals, coords = c("X", "Y"), crs = st_crs(eng_wales))
# qtm(metals_map)
# Prediction
grid <- terra::rast(eng_wales , nrows = 50, ncols = 50)
xy <- terra::xyFromCell(grid, 1:ncell(grid))
Pred_loc <- st_as_sf(as.data.frame(xy), coords = c("x", "y"),
crs = st_crs(eng_wales))
Pred_loc <- st_filter(Pred_loc, st_as_sf(eng_wales)) # filter out points outside domain
# qtm(Pred_loc)
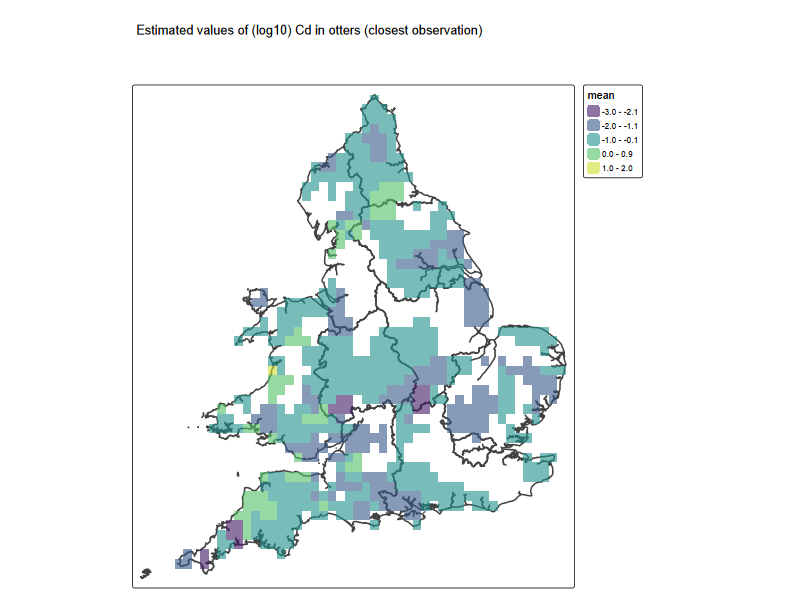
### method (1) closest obs
# Voronoi
v <-terra::voronoi(x = terra::vect(metals_map[1:250,'Cd']), bnd = eng_wales) # some bug: can't deal with last few lines
# plot(v)
# points(vect(metals_map), cex = 0.5)
# # voronoi map
tm_shape(st_as_sf(eng_wales)) + tm_polygons(alpha = 0.3) + tm_shape(metals_map) +
tm_dots("Cd", palette = "viridis")
# tm_shape(v) +
# tm_fill(col = "Cd", palette = "viridis", alpha = 0.6) + ### need changing>> what is the 'vble' column
# tm_shape(metals_map) +
# tm_dots("Cd", palette = "viridis")+
# tm_shape(eng_wales) +
# tm_borders(lwd = 2)
# raster map
resp <- st_intersection(st_as_sf(v), Pred_loc)
resp$pred <- log10(resp$Cd)
pred <- terra::rasterize(resp, grid, field = "pred", fun = "mean")
Cd_grid <- tm_shape(eng_wales) +
tm_borders(lwd = 2) +
tm_shape(pred) + tm_raster(alpha = 0.6, palette = "viridis")+
tm_title('Estimated values of (log10) Cd in otters (closest observation)
')
Cd_grid
Attaching package: ‘maps’
The following object is masked from ‘package:viridis’:
unemp
── tmap v3 code detected ───────────────────────────────────────────────────────
[v3->v4] `tm_polygons()`: use `fill_alpha` instead of `alpha`.
Warning message:
attribute variables are assumed to be spatially constant throughout all geometries
── tmap v3 code detected ───────────────────────────────────────────────────────
[v3->v4] `tm_tm_raster()`: migrate the argument(s) related to the scale of the
visual variable `col` namely 'palette' (rename to 'values') to col.scale =
tm_scale(<HERE>).
[v3->v4] `tm_raster()`: use `col_alpha` instead of `alpha`.
### method (1) closest obs
# Voronoi
# v <-terra::voronoi(x = terra::vect(st_as_sf( riv_metals[c('lon','lat', 'Cd_mean')],
# coords = c("lon", "lat"), crs = 4326) ), bnd = eng_wales)
v <-terra::voronoi(x = terra::vect(st_as_sf( riv_metals[c('easting','northing', 'Cd_mean')],
coords = c("easting", "northing"), crs = 27700) ), bnd = eng_wales)
resp <- st_intersection(st_as_sf(v), Pred_loc)
resp$pred <- log10(resp$Cd)
pred_riv <- terra::rasterize(resp, grid, field = "pred", fun = "mean")
Repeat for water quality
Warning message:
attribute variables are assumed to be spatially constant throughout all geometries
# tmap_grob(Cd_grid + tm_layout(legend.show=FALSE, frame = FALSE))
sm <- matrix(c(2.0, 1.2, 0, 1), 2, 2)
pred_sf <- st_as_sf(as.polygons(pred))
pred_sf_tilt <- pred_sf
pred_sf_tilt$geometry <- pred_sf$geometry * sm
st_crs(pred_sf_tilt) <- st_crs(pred_sf)
pred_sf_tilt2 <- pred_sf
pred_sf_tilt2$geometry <- pred_sf_tilt$geometry + c(0,-0 )
st_crs(pred_sf_tilt2) <- st_crs(pred_sf)
## River
pred_riv_sf <- st_as_sf(as.polygons(pred_riv))
pred_sf_tilt3 <- pred_riv_sf
pred_sf_tilt3$geometry <- pred_riv_sf$geometry * sm + c(0,-1e6 )
st_crs(pred_sf_tilt3) <- st_crs(pred_riv_sf)
# coarse, if not too slow
r_coarse <- resample(r_stack, pred, method="near")
# crop r_stack to England and Wales
r_coarse <- crop(r_coarse, eng_wales, mask=TRUE)
r_coarse_sf <- st_as_sf(as.polygons(r_coarse))
r_coarse_sf2 <- st_as_sf(as.polygons(r_coarse$var2))
r_coarse_sf_tilt <- r_coarse_sf
r_coarse_sf_tilt$geometry <- r_coarse_sf$geometry * sm + c(0,-1.5e6 )
st_crs(r_coarse_sf_tilt) <- st_crs(r_coarse_sf)
r_coarse_sf2_tilt <- r_coarse_sf2
r_coarse_sf2_tilt$geometry <- r_coarse_sf2$geometry * sm + c(0,-0.5e6 )
st_crs(r_coarse_sf2_tilt) <- st_crs(r_coarse_sf2)
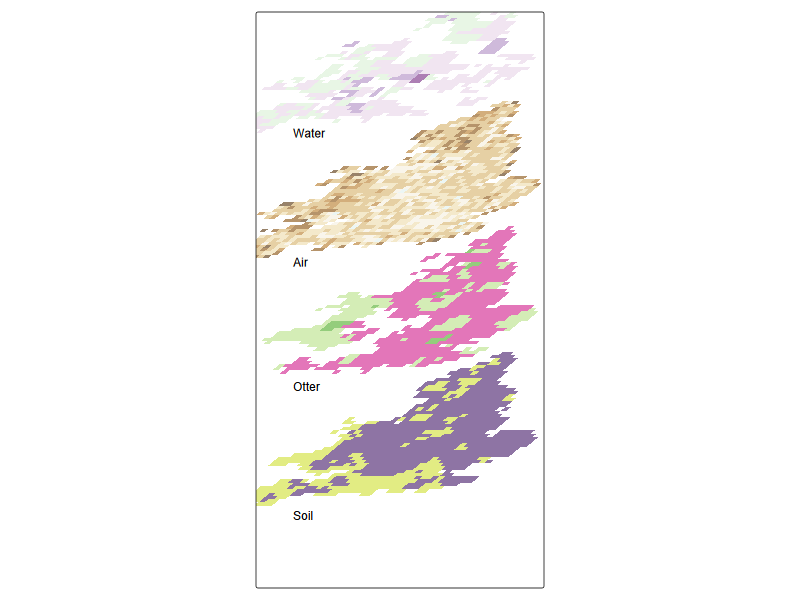
tm_shape(pred_sf_tilt3 ) + ## everything relative to this
tm_fill(c('mean'),alpha = 0.6, palette = "brewer.pi_yg") +
tm_shape(pred_sf_tilt2) +
tm_fill(c('mean'),alpha = 0.6, palette = "brewer.prgn") +
tm_shape(r_coarse_sf_tilt) +
tm_fill(c('var1'),alpha = 0.6, palette = "viridis") +
tm_shape(r_coarse_sf2_tilt) +
tm_fill(c('var2'),alpha = 0.6, palette = "brewer.br_bg") +
tm_credits('Water', position = c(0.02, 0.88) , size = 1) +
tm_credits('Air', position = c(0.02, 0.6) , size = 1) +
tm_credits('Otter', position = c(0.02, 0.33) , size = 1) +
tm_credits('Soil', position = c(0.02, 0.05) , size = 1) +
tm_layout(legend.show=FALSE, frame = TRUE, asp = 0.5)
Data cube for cadmium data across compartments
── tmap v3 code detected ───────────────────────────────────────────────────────
[v3->v4] `tm_tm_fill()`: migrate the argument(s) related to the scale of the
visual variable `fill` namely 'palette' (rename to 'values') to fill.scale =
tm_scale(<HERE>).
[v3->v4] `tm_fill()`: use `fill_alpha` instead of `alpha`.
[v3->v4] `tm_fill()`: use `fill_alpha` instead of `alpha`.
[v3->v4] `tm_fill()`: use `fill_alpha` instead of `alpha`.
[v3->v4] `tm_fill()`: use `fill_alpha` instead of `alpha`.